
Takeaways
苍穹外卖
1.软件开发流程
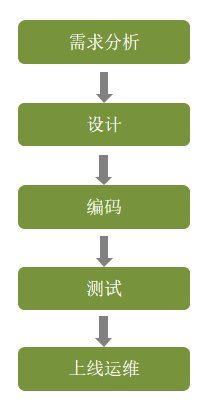
1.1完成需求规格说明书、产品原型编写。
需求规格说明书, 一般来说就是使用 Word 文档来描述当前项目的各个组成部分,如:系统定义、应用环境、功能规格、性能需求等,都会在文档中描述。
1.2设计
设计的内容包含 UI设计、数据库设计、接口设计。
UI设计:用户界面的设计,主要设计项目的页面效果,小到一个按钮,大到一个页面布局,还有人机交互逻辑的体现。
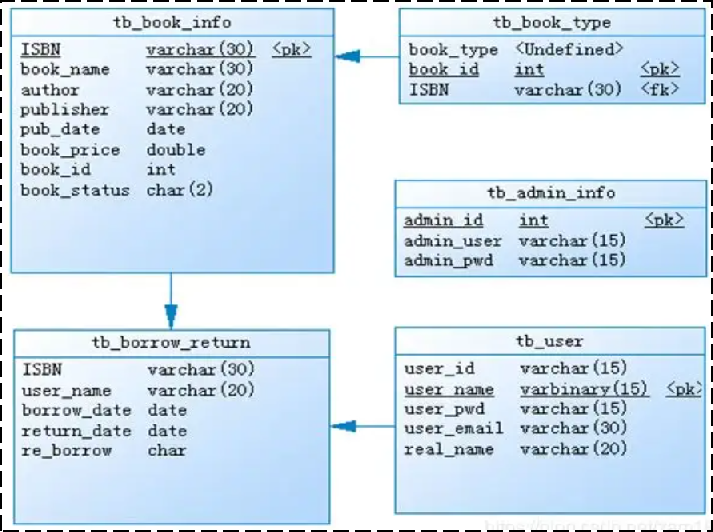
数据库设计:需要设计当前项目中涉及到哪些数据库,每一个数据库里面包含哪些表,这些表结构之间的关系是什么样的,表结构中包含哪些字段。
即是画出ER图,实体关系图
ER图(实体-关系图)是数据库设计中常用的一种图形化工具,用于描述数据库中实体(Entity)之间的关系(Relationship)和属性(Attribute)。它是一种概念模型,用于可视化数据库结构,帮助设计者理清数据模型的结构和关系,从而更好地设计数据库。
以下是 ER 图中常见的几个要素:
实体(Entity):表示数据库中存储的现实世界中的一个事物,可以是一个对象、一个概念或者一个事件。每个实体通常有属性,用来描述实体的特征。
属性(Attribute):实体的特征或者属性,用于描述实体的性质或特征,例如一个人实体可以有姓名、年龄等属性。
关系(Relationship):表示实体之间的关联或联系,描述实体之间的联系方式和约束条件。关系可以是一对一、一对多或者多对多的。
主键(Primary Key):实体中的一个属性或属性组合,能够唯一标识实体的属性。在 ER 图中通常用下划线或者加粗表示。
外键(Foreign Key):表示一个实体中的属性,引用了另一个实体的主键,用来建立实体之间的关联关系。
ER 图通过图形化的方式展现了数据库中实体之间的关系,有助于开发人员、数据库管理员和用户理解数据库的结构和设计。在数据库设计阶段,ER 图是一个重要的工具,可以用来进行概念建模、需求分析、设计评审和沟通交流。
接口设计:通过分析原型图,首先,粗分析每个页面有多少个接口,然后,再细分析,每个接口的传入参数,返回值参数,同时明确接口的路径以及请求方式

1.3编码
编写项目代码、并完成单元测试。
项目代码编写:作为软件开发工程师,我们需要对项目的模块功能分析后,进行编码实现。
单元测试:编码实现完毕后,进行单元测试,单元测试通过后再进入到下一阶段。
1.4测试
在该阶段中主要由测试人员, 对部署在测试环境的项目进行功能测试, 并出具测试报告。
1.5上线运维
在项目上线之前, 会由运维人员准备服务器上的软件环境安装、配置, 配置完毕后, 再将我们开发好的项目,部署在服务器上运行。
2.角色分工
| 岗位/角色 | 对应阶段 | 职责/分工 |
|---|---|---|
| 项目经理 | 全阶段 | 对整个项目负责,任务分配、把控进度 |
| 产品经理 | 需求分析 | 进行需求调研,输出需求调研文档、产品原型等 |
| UI设计师 | 设计 | 根据产品原型输出界面效果图 |
| 架构师 | 设计 | 项目整体架构设计、技术选型等 |
| 开发工程师 | 编码 | 功能代码实现 |
| 测试工程师 | 测试 | 编写测试用例,输出测试报告 |
| 运维工程师 | 上线运维 | 软件环境搭建、项目上线 |
2.1项目介绍
1). 管理端功能
员工登录/退出 , 员工信息管理 , 分类管理 , 菜品管理 , 套餐管理 , 菜品口味管理 , 订单管理 ,数据统计,来单提醒。
2). 用户端功能
微信登录 , 收件人地址管理 , 用户历史订单查询 , 菜品规格查询 , 购物车功能 , 下单 , 支付、分类及菜品浏览。
1). 管理端
餐饮企业内部员工使用。 主要功能有:
| 模块 | 描述 |
|---|---|
| 登录/退出 | 内部员工必须登录后,才可以访问系统管理后台 |
| 员工管理 | 管理员可以在系统后台对员工信息进行管理,包含查询、新增、编辑、禁用等功能 |
| 分类管理 | 主要对当前餐厅经营的 菜品分类 或 套餐分类 进行管理维护, 包含查询、新增、修改、删除等功能 |
| 菜品管理 | 主要维护各个分类下的菜品信息,包含查询、新增、修改、删除、启售、停售等功能 |
| 套餐管理 | 主要维护当前餐厅中的套餐信息,包含查询、新增、修改、删除、启售、停售等功能 |
| 订单管理 | 主要维护用户在移动端下的订单信息,包含查询、取消、派送、完成,以及订单报表下载等功能 |
| 数据统计 | 主要完成对餐厅的各类数据统计,如营业额、用户数量、订单等 |
2). 用户端
移动端应用主要提供给消费者使用。主要功能有:
| 模块 | 描述 |
|---|---|
| 登录/退出 | 用户需要通过微信授权后登录使用小程序进行点餐 |
| 点餐-菜单 | 在点餐界面需要展示出菜品分类/套餐分类, 并根据当前选择的分类加载其中的菜品信息, 供用户查询选择 |
| 点餐-购物车 | 用户选中的菜品就会加入用户的购物车, 主要包含 查询购物车、加入购物车、删除购物车、清空购物车等功能 |
| 订单支付 | 用户选完菜品/套餐后, 可以对购物车菜品进行结算支付, 这时就需要进行订单的支付 |
| 个人信息 | 在个人中心页面中会展示当前用户的基本信息, 用户可以管理收货地址, 也可以查询历史订单数据 |
2.3 技术选型
关于本项目的技术选型, 我们将会从 用户层、网关层、应用层、数据层 这几个方面进行介绍,主要用于展示项目中使用到的技术框架和中间件等。
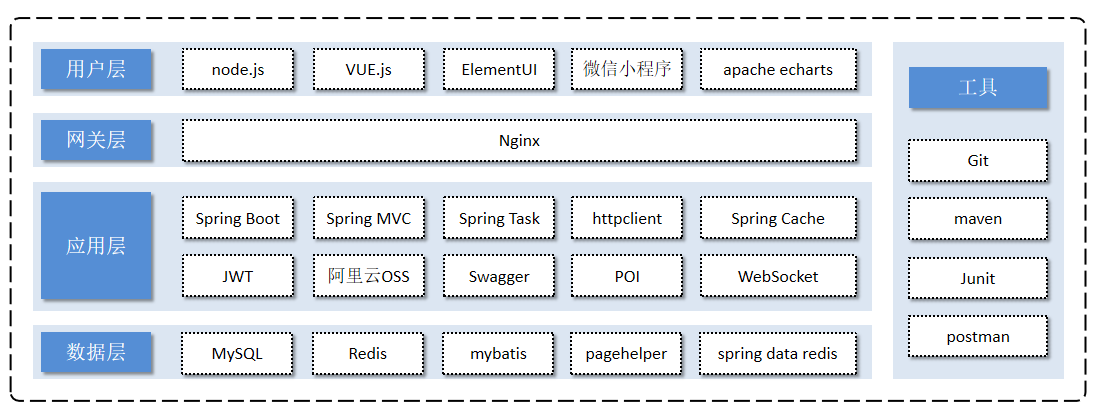
1). 用户层
本项目中在构建系统管理后台的前端页面,我们会用到H5、Vue.js、ElementUI、apache echarts(展示图表)等技术。而在构建移动端应用时,我们会使用到微信小程序。
2). 网关层
Nginx是一个服务器,主要用来作为Http服务器,部署静态资源,访问性能高。在Nginx中还有两个比较重要的作用: 反向代理和负载均衡, 在进行项目部署时,要实现Tomcat的负载均衡,就可以通过Nginx来实现。
3). 应用层
SpringBoot: 快速构建Spring项目, 采用 “约定优于配置” 的思想, 简化Spring项目的配置开发。
SpringMVC:SpringMVC是spring框架的一个模块,springmvc和spring无需通过中间整合层进行整合,可以无缝集成。
Spring Task: 由Spring提供的定时任务框架。
httpclient: 主要实现了对http请求的发送。
Spring Cache: 由Spring提供的数据缓存框架
JWT: 用于对应用程序上的用户进行身份验证的标记。
阿里云OSS: 对象存储服务,在项目中主要存储文件,如图片等。
Swagger: 可以自动的帮助开发人员生成接口文档,并对接口进行测试。
POI: 封装了对Excel表格的常用操作。
WebSocket: 一种通信网络协议,使客户端和服务器之间的数据交换更加简单,用于项目的来单、催单功能实现。
4). 数据层
MySQL: 关系型数据库, 本项目的核心业务数据都会采用MySQL进行存储。
Redis: 基于key-value格式存储的内存数据库, 访问速度快, 经常使用它做缓存。
Mybatis: 本项目持久层将会使用Mybatis开发。
pagehelper: 分页插件。
spring data redis: 简化java代码操作Redis的API。
5). 工具
git: 版本控制工具, 在团队协作中, 使用该工具对项目中的代码进行管理。
maven: 项目构建工具。
junit:单元测试工具,开发人员功能实现完毕后,需要通过junit对功能进行单元测试。
postman: 接口测工具,模拟用户发起的各类HTTP请求,获取对应的响应结果。
2.4 nginx
对登录功能测试完毕后,接下来,我们思考一个问题:前端发送的请求,是如何请求到后端服务的?
前端请求地址:http://localhost/api/employee/login
后端接口地址:http://localhost:8080/admin/employee/login
nginx反向代理:就是将前端发送的动态请求由nginx转发到后端服务器
nginx 反向代理的好处:
提高访问速度
因为nginx本身可以进行缓存,如果访问的同一接口,并且做了数据缓存,nginx就直接可把数据返回,不需要真正地访问服务端,从而提高访问速度。
进行负载均衡
所谓负载均衡,就是把大量的请求按照我们指定的方式均衡的分配给集群中的每台服务器。
保证后端服务安全
因为一般后台服务地址不会暴露,所以使用浏览器不能直接访问,可以把nginx作为请求访问的入口,请求到达nginx后转发到具体的服务中,从而保证后端服务的安全。
nginx 反向代理的配置方式:
1 | server{ |
proxy_pass:该指令是用来设置代理服务器的地址,可以是主机名称,IP地址加端口号等形式。
如上代码的含义是:监听80端口号, 然后当我们访问 http://localhost:80/api/../..这样的接口的时候,它会通过 location /api/ {} 这样的反向代理到 http://localhost:8080/admin/上来。
接下来,进到nginx-1.20.2\conf,打开nginx配置
1 | # 反向代理,处理管理端发送的请求 |
2). nginx 负载均衡
当如果服务以集群的方式进行部署时,那nginx在转发请求到服务器时就需要做相应的负载均衡。其实,负载均衡从本质上来说也是基于反向代理来实现的,最终都是转发请求。
nginx 负载均衡的配置方式:
1 | upstream webservers{ |
upstream:如果代理服务器是一组服务器的话,我们可以使用upstream指令配置后端服务器组。
如上代码的含义是:监听80端口号, 然后当我们访问 http://localhost:80/api/../..这样的接口的时候,它会通过 location /api/ {} 这样的反向代理到 http://webservers/admin,根据webservers名称找到一组服务器,根据设置的负载均衡策略(默认是轮询)转发到具体的服务器。
注:upstream后面的名称可自定义,但要上下保持一致。
nginx 负载均衡策略:
| 名称 | 说明 |
|---|---|
| 轮询 | 默认方式 |
| weight | 权重方式,默认为1,权重越高,被分配的客户端请求就越多 |
| ip_hash | 依据ip分配方式,这样每个访客可以固定访问一个后端服务 |
| least_conn | 依据最少连接方式,把请求优先分配给连接数少的后端服务 |
| url_hash | 依据url分配方式,这样相同的url会被分配到同一个后端服务 |
| fair | 依据响应时间方式,响应时间短的服务将会被优先分配 |
具体配置方式:
2.5登陆加密MD5
调用spring框架的DigestUtils
1 | password = DigestUtils.md5DigestAsHex(password.getBytes()); |
3.导入接口文档
在真实的企业开发中,接口设计过程其实是一个非常漫长的过程,可能需要多次开会讨论调整,甚至在开发的过程中才会发现某些接口定义还需要再调整,这种情况其实是非常常见的

第一步:定义接口,确定接口的路径、请求方式、传入参数、返回参数。
第二步:前端开发人员和后端开发人员并行开发,同时,也可自测。
第三步:前后端人员进行连调测试。
第四步:提交给测试人员进行最终测试。
4. Swagger
Swagger 是一个规范和完整的框架,用于生成、描述、调用和可视化 RESTful 风格的 Web 服务(https://swagger.io/)。 它的主要作用是:
使得前后端分离开发更加方便,有利于团队协作
接口的文档在线自动生成,降低后端开发人员编写接口文档的负担
功能测试
Spring已经将Swagger纳入自身的标准,建立了Spring-swagger项目,现在叫Springfox。通过在项目中引入Springfox ,即可非常简单快捷的使用Swagger。
knife4j是为Java MVC框架集成Swagger生成Api文档的增强解决方案,前身是swagger-bootstrap-ui,取名knife4j是希望它能像一把匕首一样小巧,轻量,并且功能强悍!
目前,一般都使用knife4j框架。
项目启动后的访问地址:http://localhost:8080/doc.html
访问界面如下:

4.1使用步骤
新版型详情参见:
SpringBoot从入门到精通(二十一)SpringBoot3 集成Swagger3 - 知乎 (zhihu.com)
导入 knife4j 的maven坐标
在pom.xml中添加依赖
1
2
3
4<dependency>
<groupId>com.github.xiaoymin</groupId>
<artifactId>knife4j-spring-boot-starter</artifactId>
</dependency>我自己是springboot3.1.4,老版本不适配了,搞了我好久
1
2
3
4
5
6<dependency>
<groupId>com.github.xiaoymin</groupId>
<artifactId>knife4j-openapi3-jakarta-spring-boot-starter</artifactId>
<version>4.5.0</version>
</dependency>在配置类中加入 knife4j 相关配置
新版本是
WebMvcConfiguration.java
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19/**
* 通过knife4j生成接口文档
* @return
*/
public Docket docket() {
ApiInfo apiInfo = new ApiInfoBuilder()
.title("苍穹外卖项目接口文档")
.version("2.0")
.description("苍穹外卖项目接口文档")
.build();
Docket docket = new Docket(DocumentationType.SWAGGER_2)
.apiInfo(apiInfo)
.select()
.apis(RequestHandlerSelectors.basePackage("com.sky.controller"))
.paths(PathSelectors.any())
.build();
return docket;
}新版本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20import io.swagger.v3.oas.models.ExternalDocumentation;
import io.swagger.v3.oas.models.OpenAPI;
import io.swagger.v3.oas.models.info.Info;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
public class OpenAPIConfig {
public OpenAPI openAPI() {
return new OpenAPI()
.info(new Info()
.title("测试 title")
.description("SpringBoot3 集成 Swagger3")
.version("v1"))
.externalDocs(new ExternalDocumentation()
.description("项目API文档")
.url("/"));
}
}设置静态资源映射,否则接口文档页面无法访问
WebMvcConfiguration.java
1
2
3
4
5
6
7
8/**
* 设置静态资源映射
* @param registry
*/
protected void addResourceHandlers(ResourceHandlerRegistry registry) {
registry.addResourceHandler("/doc.html").addResourceLocations("classpath:/META-INF/resources/");
registry.addResourceHandler("/webjars/**").addResourceLocations("classpath:/META-INF/resources/webjars/");
}访问测试
接口文档访问路径为 http://ip:port/doc.html —> http://localhost:8080/doc.html
4.2常用注解
通过注解可以控制生成的接口文档,使接口文档拥有更好的可读性,常用注解如下:
| 注解 | 说明 |
|---|---|
| @Api | 用在类上,例如Controller,表示对类的说明 |
| @ApiModel | 用在类上,例如entity、DTO、VO |
| @ApiModelProperty | 用在属性上,描述属性信息 |
| @ApiOperation | 用在方法上,例如Controller的方法,说明方法的用途、作用 |
接下来,使用上述注解,生成可读性更好的接口文档
默认是可以不配置任何注解的,不过增加一些注解可以使swagger可读性更加好。
| 注解SpringBoot3 版本 | 替换旧注解 SpringBoot2 版本 | 描述 |
|---|---|---|
| @Tag | @Api | 用于标注一个Controller(Class)。 在默认情况下,Swagger-Core只会扫描解析具有@Api注解的类,而会自动忽略其他类别资源(JAX-RS endpoints,Servlets等等)的注解。 |
| @Operation | @ApiOperation | 用于对一个操作或HTTP方法进行描述。 具有相同路径的不同操作会被归组为同一个操作对象。 不同的HTTP请求方法及路径组合构成一个唯一操作。 |
| @Parameter | @ApiParam | @Parameter作用于请求方法上,定义api参数的注解。 |
| @Parameters、 @Parameter | @ApiImplicitParams、@ApiImplicitParam | 都可以定义参数 (1)@Parameters:用在请求的方法上,包含一组参数说明 (2)@Parameter:对单个参数的说明 |
| io.swagger.v3.oas.annotations新包中的@ApiResponses、@ApiResponse | 旧包io.swagger.annotations中的@ApiResponses、@ApiResponse | 进行方法返回对象的说明。 |
| @Schema | @ApiModel、@ApiModelProperty | @Schema用于描述一个Model的信息(这种一般用在post创建的时候,使用@RequestBody这样的场景)。 |
新增SwaggerController.java,配置具体Swagger常用注解
1 | import io.swagger.v3.oas.annotations.media.Schema; |
功能实现
这里就不大段复制代码了,写一下大概得流程和自己的理解吧,主要之前在Web里面也实现过,看一看实现的区别吧
1.项目框架描述
主体sky-take-out由三个模块实现
common 、pojo、 server

Common
constant:一些常量类
context:存储的通常是与上下文(Context)相关的类和接口,可能包括与线程上下文、应用程序上下文等相关的功能和工具类。
enumeration:一般用于存储枚举(Enumeration)相关的类。枚举是一种特殊的数据类型,用于表示一组有限的可能取值。在 Java 中,枚举通常用于表示一组相关的常量或选项,它们在逻辑上是有序的,并且具有固定数量的取值。
exception:处理各种异常的类
json:将Java对象转换为JSON格式的数据的类
properties:阿里云OSS,JWT,WeChat等的配置类
result:最后封装相应的结果类
utils:阿里云OSS,JWT,WeChat,Http等的工具类

Pojo
- dto:前端接口响应数据的封装类,只有实体类的部分数据(前端给后端响应的)
- entity:顾名思义,存放实体类,(与数据库对应的)
- vo:前端需要哪儿些内容,实体类对应不上,新建一个vo类去封装(后端给前端响应的)

Server
在一个典型的Java Web应用中,这些包的作用和存放的类通常如下:
config 包:存放配置类,用于配置应用程序的各种组件,例如数据库连接、缓存配置、安全配置等。这些配置类通常使用注解
@Configuration标记,并且可能包含@Bean方法用于定义和初始化各种Bean。controller 包:存放控制器类,用于处理HTTP请求和响应。控制器类通常使用注解
@Controller或@RestController标记,其中@RestController通常用于RESTful风格的控制器。控制器类中的方法通常使用@RequestMapping或其他注解映射到特定的HTTP请求路径,并返回响应给客户端。handler 包:存放异常处理类,用于处理应用程序中的异常情况。异常处理类通常使用
@ControllerAdvice或@ExceptionHandler注解标记,用于捕获和处理全局异常或特定类型的异常。interceptor 包:存放拦截器类,用于拦截和处理HTTP请求和响应。拦截器类通常实现
HandlerInterceptor接口,并且可以在请求处理之前、之后或完成之后执行特定的逻辑,例如身份验证、日志记录等。mapper 包:存放数据访问层(DAO)的接口或类,用于定义数据访问的接口和方法。通常与MyBatis或其他持久化框架结合使用,用于执行数据库操作和管理持久化对象。
service 包:存放服务层(Service)的类,用于实现应用程序的业务逻辑。服务类通常包含业务逻辑的实现方法,并且可能依赖于DAO(数据访问对象)进行数据访问和持久化操作。服务类通常使用注解
@Service标记,以便Spring框架能够自动扫描和管理。

2.新增员工


新增员工对应的实体类
因为我们员工类定义的属性比较多
但是在添加员工的过程中,又不需要那么多的属性
所以根据新增员工接口设计对应的DTO类
当然也可以用我们的实体类去封装前端提交的数据
注意:当前端提交的数据和实体类中对应的属性差别比较大时,建议使用DTO来封装数据**
然后就是常规三段式:
controller层接受前端请求,调用service层的save方法,在service层接口定义save方法,并且在serviceiml实现类中实现save方法
注意:因为接受的是dto,要在save中补全,再调用mapper层insert插入
在mapper层,用@Insert或者MybatisPlus直接插入数据库中
1 | public void save(EmployeeDTO employeeDTO) { |
问题1:若录入用户名已经存在,该如何处理异常?
解决:通过全局异常处理器来处理
进入到sky-server模块,com.sky.hander包下,GlobalExceptionHandler.java添加方法
1 | /** |
问题2:新增员工时,如何获取创建人和修改人的ID?
解决1:直接注入HTTP对象,拿到Token去解析(web方法)
1 | //为什么可以自动注入,可以理解为spring自动交给IOC容器管理了 |
解决2:在拦截器中,根据请求头Token携带的JWT令牌,用JWT工具类反向解析出用户ID,解析出ID后,如何传递给service层的save方法呢?
通过ThreadLocal进行传递。
ThreadLocal
介绍:
ThreadLocal不是一个Thread,而是Thread的局部变量
ThreadLocal为每一个线程单独提供一份存储空间,具有线程隔离的效果,只有在线程内才能获取到对应的数值,线程外则不能访问
常用方法:
- public void set(T value) 设置当前线程的线程局部变量的值
- public T get() 返回当前线程所对应的线程局部变量的值
- public void remove() 移除当前线程的线程局部变量

1 | /////将用户id存储到ThreadLocal//////// |
在拦截器中,将解析出来的ID放入线程中
在service层中取出线程局部变量中的值
3.员工分页查询
业务规则:
- 根据页码展示员工信息
- 每页展示10条数据
- 分页查询时可以根据需要,输入员工姓名进行查询
分页查询页面中,前端传递三个参数,name,page,pageSize


使用泛型参数
实现思路:dto类封装请求参数
对所有的分页查询对象,都统一定义封装为PageResult对象
再封装到Result
1 | public class PageResult implements Serializable { |
controller层: 调用service层的方法返回pageResult对象,再封装到Result中返回
service层:调用分页查询的插件方法,PageHelper.startPage(页码,分页数)
1 | public PageResult pageQuery(EmployeePageQueryDTO employeePageQueryDTO) { |
再调用mapper层的方法返回page
mapper:因为name参数不一定传进来,所以要在xml文件中写动态SQL
1 | <select id="pageQuery" resultType="com.sky.entity.Employee"> |
PageHelper
是一个用于 MyBatis 的分页插件,它的执行逻辑如下:
拦截 SQL 语句:当调用
PageHelper.startPage()方法设置分页参数后,PageHelper 会拦截后续执行的 SQL 语句。解析 SQL 语句:PageHelper 会解析被拦截的 SQL 语句,提取其中的查询语句和条件。
生成分页 SQL:根据设置的分页参数,PageHelper 会根据原始的查询语句生成对应的分页 SQL,包括对应的 LIMIT 或者 ROW_NUMBER() 等语句,以实现数据库分页查询。
执行分页查询:PageHelper 将修改后的分页 SQL 交给 MyBatis 执行,MyBatis 查询得到的结果已经被分页处理,只包含指定页码范围内的数据。
封装查询结果:PageHelper 将查询结果封装成 Page 对象返回,该对象包含了分页信息和查询结果。
总的来说,PageHelper 主要通过拦截 SQL 语句、解析并修改 SQL、执行分页查询,最终封装查询结果来实现分页功能。这样的设计可以使得分页查询逻辑与业务逻辑分离,提高了代码的可维护性和可扩展性。
消息转换器
Spring MVC 的消息转换器(Message Converters)负责在 HTTP 请求和响应的过程中,将请求体和响应体的数据与 Java 对象之间进行相互转换。它们将来自客户端的请求数据转换为 Java 对象,以便在控制器中进行处理,并将处理结果转换为客户端可接受的格式返回。
消息转换器在 Spring MVC 中扮演着重要的角色,因为它们使得开发人员可以轻松地处理各种类型的数据,例如 JSON、XML、HTML、文本等。Spring MVC 框架提供了一组默认的消息转换器来处理常见的数据格式转换,例如:
MappingJackson2HttpMessageConverter:用于将 JSON 数据转换为 Java 对象,以及将 Java 对象转换为 JSON 数据。StringHttpMessageConverter:用于处理字符串数据的转换。MarshallingHttpMessageConverter:用于处理 XML 数据的转换。
开发人员还可以根据需要自定义消息转换器,以支持其他数据格式的转换。通过扩展 WebMvcConfigurer 接口或重写 WebMvcConfigurationSupport 类中的 extendMessageConverters 方法,可以将自定义的消息转换器添加到 Spring MVC 中。
问题:操作时间段显示有问题
解决方式:
1). 方式一
在属性上加上注解,对日期进行格式化

但这种方式,需要在每个时间属性上都要加上该注解,使用较麻烦,不能全局处理。
2). 方式二(推荐 )
在WebMvcConfiguration中扩展SpringMVC的消息转换器,统一对日期类型进行格式处理
1 | /** |
说实话,我看不懂这里的消息转换器的代码
4.启用禁用员工的账号
业务规则:
- 可以对状态为“启用” 的员工账号进行“禁用”操作
- 可以对状态为“禁用”的员工账号进行“启用”操作
- 状态为“禁用”的员工账号不能登录系统

controller层:路径参数用@PathVariable接收,查询参数query,用名字相同的参数封装
service层:创建对象,设置对象的ID,query
mapper层:本来是可以直接用注解写
1 | @Update |
但是为了其他跟新的可以也直接调用这个方法,所以写动态SQL
1 | <update id="update" parameterType="Employee"> |
5.编辑员工
先查询用于页面的回显,再更新员工的信息
页面回显:
controller:@PathVariable接收路径参数{id}
servide:定义getById方法
mapper:注解@select * from emp where id = ?
跟新员工:
controller:@RequestBody接收body参数封装到类中
service:new实体 对象,拷贝dto到实体类,在设置跟新时间等其它参数
mapper:update的动态SQL,刚才已经写过
6.导入分类模块功能代码
基础的基于分类模块的,增删改查,直接导入
7.公共字段填充
在新增员工或者新增菜品分类时需要设置创建时间、创建人、修改时间、修改人等字段,在编辑员工或者编辑菜品分类时需要设置修改时间、修改人等字段。这些字段属于公共字段,也就是也就是在我们的系统中很多表中都会有这些字段,如下:
| 序号 | 字段名 | 含义 | 数据类型 |
|---|---|---|---|
| 1 | create_time | 创建时间 | datetime |
| 2 | create_user | 创建人id | bigint |
| 3 | update_time | 修改时间 | datetime |
| 4 | update_user | 修改人id | bigint |
而针对于这些字段,我们的赋值要在很多请求中进行
新增,编辑,员工,菜品等等
果都按照上述的操作方式来处理这些公共字段, 需要在每一个业务方法中进行操作, 编码相对冗余、繁琐,那能不能对于这些公共字段在某个地方统一处理,来简化开发呢?
答案是可以的,我们使用AOP切面编程,实现功能增强,来完成公共字段自动填充功能。
| 序号 | 字段名 | 含义 | 数据类型 | 操作类型 |
|---|---|---|---|---|
| 1 | create_time | 创建时间 | datetime | insert |
| 2 | create_user | 创建人id | bigint | insert |
| 3 | update_time | 修改时间 | datetime | insert、update |
| 4 | update_user | 修改人id | bigint | insert、update |
1). 在新增数据时, 将createTime、updateTime 设置为当前时间, createUser、updateUser设置为当前登录用户ID。
2). 在更新数据时, 将updateTime 设置为当前时间, updateUser设置为当前登录用户ID。
实现步骤:
1.自定义注解@a,用于表示需要进行公共字段填充的方法
2.自定义切面类AOP ,统一拦截加入注解@a的方法,通过反射为公共字段赋值
3.在mapper中的方法上,加入@a注解
技术点:枚举,注解,AOP,反射
1 | 反射的概念 |
自定义切面,实现公共逻辑的处理问题
反射的逻辑太复杂了,尤其这里还是枚举,注解,AOP,反射集合在了一起
1 |
|
一行代码一行代码的注释,反射逻辑太复杂了,看了三遍这段
8.新增菜品
业务规则:
- 菜品名称必须是唯一的
- 菜品必须属于某个分类下,不能单独存在
- 新增菜品时可以根据情况选择菜品的口味
- 每个菜品必须对应一张图片
接口设计:
- 根据类型查询分类(已完成)
- 文件上传。web中已完成
1 | 阿里OSS上传流程 |
- 新增菜品:
新增菜品,其实就是将新增页面录入的菜品信息插入到dish表,如果添加了口味做法,还需要向dish_flavor表插入数据。所以在新增菜品时,涉及到两个表:
| 表名 | 说明 |
|---|---|
| dish | 菜品表 |
| dish_flavor | 菜品口味表 |
1 | 1.设计DTO类,@RequestBody将前端的参数全部封装 |
9.菜品分页查询
业务规则:
- 根据页码展示菜品信息
- 每页展示10条数据
- 分页查询时可以根据需要输入菜品名称、菜品分类、菜品状态进行查询
1 | 1.因为要查询菜品的信息,以及菜品所在的分类,所以要查两张表 |
spring3版本的分页查询插件的版本一定不能太低,否则分页不了,我真的!!!
debug排查了一晚上的代码,都逼得我去看PageHelper的源码了
原来不是代码写错了,只是版本太低不兼容的问题
10删除菜品
业务规则:
- 可以一次删除一个菜品,也可以批量删除菜品
- 起售中的菜品不能删除
- 被套餐关联的菜品不能删除
- 删除菜品后,关联的口味数据也需要删除掉
接口设计

表设计

注意事项:
- 在dish表中删除菜品基本数据时,同时,也要把关联在dish_flavor表中的数据一块删除。
- setmeal_dish表为菜品和套餐关联的中间表。
- 若删除的菜品数据关联着某个套餐,此时,删除失败。
- 若要删除套餐关联的菜品数据,先解除两者关联,再对菜品进行删除。
1 | 1.@requestParame接收,封装为List<Long> |
1 |
|
11.修改菜品
5.1.2 接口设计
通过对上述原型图进行分析,该页面共涉及4个接口。
接口:
- 根据id查询菜品
- 根据类型查询分类(已实现)
- 文件上传(已实现)
- 修改菜品
1 | //查询菜谱:接收DTO,根据id查菜品,根据id查口味,封装到VO响应给前端 |








