
JavaWeb笔记
JavaWeb开发
自己在学习web知识时候记得一些笔记,有三万字
- 它打通了从前端 => MySQL => Java Web => SSM => Spring Boot => Maven 这一套技术栈
- 它包含了像 Postman、MySQL 图形界面等开发工具的使用
- 它包含了像登录校验(JWT)、文件上传等常见业务的实践
- 它包含了 AOP 应用、SpringBoot 原理、Maven 高级等进阶知识
初识web前端
用户在浏览器页面输入网址,是如何得到响应的页面数据的?
1.浏览器根据请求的URL网址,查看缓存,如果资源未缓存,则
2.交给DNS域名解析,转换为服务器的ip地址,向服务器发起请求
3.建立tcp连接:三次握手:
第一次握手:客户端向服务端发送数据包,选择一个起始序列号ISN,表示想建立连接
第二次握手:服务端收到客户端的请求后,确认客户端请求发送带确认标记的数据包,也包括服务端的ISN
第三次握手:客户端收到数据包后,明确了从客户端到服务器之间的数据传输的正常的,都确认了对方的ISN
三次握手的目的是:确保双方能够接受和发送数据,同步双方的初始序列号ISN,这样就建立了可靠的链接,可以惊进行后续的通信
在握手的过程中,如果某个阶段数据包丢失或者延迟,tcp协议会等待一段时间后,重新发送和接收数据,直到建立连接或者放弃链接,
4.HTTP请求响应:握手建立连接成功后,客户端发起HTTP请求:包含要访问的信息
5.服务器处理请求:服务器收到HTTP请求后,根据请求的资源和参数执行相应的处理,会涉及到数据库的查询和业务逻辑的处理
6.服务器返回HTTP响应:根据HTTP响应协议,返回包括状态码,响应头,响应体等等
7.浏览器接受响应:接收到后,开始处理,解析HTML文件,解析CSS,构建DOM树,布局和绘制,js代码的执行,最终呈现页面等等(涉及到前端的知识)
HTML:负责网页的结构(页面和元素)
CSS:负责网页的表现(页面元素的外观,位置,颜色大小等)
JS:负责网页的行为(交互,动态,逻辑效果等等)
HTML:HyperText Markup Language超文本标记语言,除了文本,还能定义图片,音频,视频等内容
CSS:Cascading Style Sheet 层叠样式表,用于控制页面的样式
JavaScript:跨平台的面向对象的语言,用于网页的交互,不需要编译运行,直接用于浏览器的解释就可以
JSON对象:JavaScript Object Notation,JS对象标记法
1 | { |
BOM对象:Browser Object model 浏览器对象模型,将js的各个组成部分分装成对象
1 | 对象名称 描述 |
Vue概述
Vue是一套前端框架,免除原生js中的DOM操作,简化书写
基于MVVM的思想:Model-View-ViewModel
1 | model:数据模型,特指前端中通过请求从后端获取数据 |
1 | Vue的快速入门 |
Vue生命周期:
1 | 指的是:Vue对象从创建到销毁的全过程,Vue的生命周期包括8个阶段,每触发一个生命周期,就会自动执行一个生命周期的方法 |
Ajax:
(Asynchronous JavaScript and XML)
是一种用于在不重新加载整个页面的情况下,通过后台与服务器进行异步通信的技术
1 | 概念:异步的js和xml |
Axios:
对原生Ajax的封装,简化书写
1 |
|
YApi:
接口文档管理平台
Vue组件库
Vue组件库Element
Element:饿了么开发,基于Vue2.0的桌面组件库
组件:超链接,按钮,图片,表格表单等
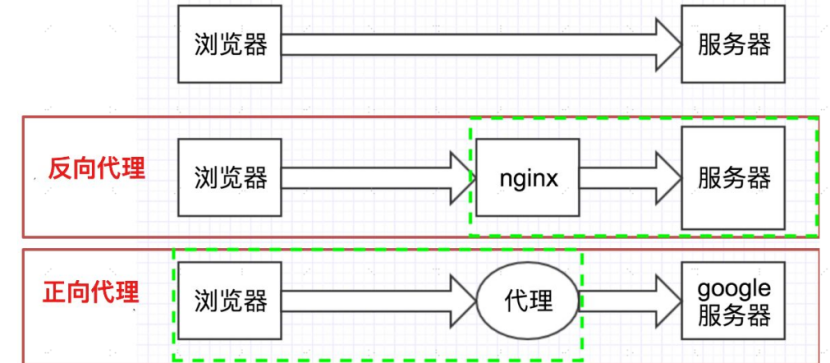
Nginx服务器
1 | Nginx是一个高性能、可靠性强的开源Web服务器软件,也可以用作反向代理服务器、负载均衡器和 HTTP缓存。 |
Maven
Maven简介
一款基于JAVA平台的项目管理和整合工具,将项目开发和管理过程,抽象成一个项目对象模型POM,只需要做一些简单的配置,
Maven就可以自动完成项目的编译,测试,打包,部署
pom.xml(配置文件) –> POM (项目对象)–> 依赖管理 –>本地仓库–>私服–>中央仓库
构建生命周期阶段
通过一些插件–>生成jar包,源代码,帮助文档,XML等
Maven作用:
项目构建:提供方便的,跨平台的自动化构建方式
依赖管理:管理项目依赖的资源(jar包),避免资源间的版本冲突
统一开发结构:提供标准的,统一的项目结构
1 | 自己组织的话:基于java的项目构建和管理的工具,主要作用有仨:1.依赖管理:传统手动导入的话很麻烦,还会有jar包之间的冲突(比如要升级一个版本,其他相关的jar包版本都要升级)使用Maven管理的话,直接在pom.xml文件中用修改dependence中的即可,2.统一开发的结构:比如就是我们开发工具是常用的是IDAE,当然也有其他的工具,eclipse等,提供这种统一的开发结构就能让项目在不同的平台哦也能运行 3、项目构建:提供项目周期中的各种插件:包括项目的清理(clean),编译(compiler),打包(jar)等等 |
1 | 创建Maven工程:配置Maven环境:使用本地安装的Maven,修改配置文件以及本地仓库 |
Maven基本概念:仓库,坐标
仓库:用于存储资源,包含各种jar包
本地(个人开发者)—局域网—>私服(企业服务器)–>中央仓库(Maven团队)
本地仓库:
远程仓库: 私服,中央仓库
坐标:Maven中坐标用于描述仓库资源的位置
坐标组成:
groupID:项目组织
artifactID:项目名称
version:版本号
packageing:打包方式
坐标作用:找到资源的位置,通过标识将资源的识别与下载交给机器
举例:
1 | <project> |
依赖传递:
直接依赖:在当前项目中通过依赖配置建立依赖关系
间接依赖:通过依赖的依赖,间接依赖其他资源
依赖传递的冲突问题:路径优先,层级越深,优先度越低
可选依赖:对外隐藏 optional
1 | <optional>true<optional> |
排除依赖 exclusion
1 | <dependency> |
依赖范围:主程序,测试程序,参与打包
依赖的jar默认情况下是可以在任何地方使用的
1 | <scope> compile </scope> |
依赖范围的传递性:
项目构建生命周期:
clean
default:主要生命周期,用于构建应用程序
site:
插件:插件与生命周期的阶段绑定,执行到对应生命周期时,执行对应插件的功能
web分析

浏览器:
输入网址:
http://192.168.100.11:8080/hello通过IP地址192.168.100.11定位到网络上的一台计算机
我们之前在浏览器中输入的localhost,就是127.0.0.1(本机)
通过端口号8080找到计算机上运行的程序
localhost:8080, 意思是在本地计算机中找到正在运行的8080端口的程序/hello是请求资源位置
- 资源:对计算机而言资源就是数据
- web资源:通过网络可以访问到的资源(通常是指存放在服务器上的数据)
localhost:8080/hello,意思是向本地计算机中的8080端口程序,获取资源位置是/hello的数据- 8080端口程序,在服务器找/hello位置的资源数据,发给浏览器
- 资源:对计算机而言资源就是数据
服务器:(可以理解为ServerSocket)
- 接收到浏览器发送的信息(如:/hello)
- 在服务器上找到/hello的资源
- 把资源发送给浏览器
HTTP协议
HTTP:Hyper Text Transfer Protocol(超文本传输协议),规定了浏览器与服务器之间数据传输的规则。
http协议要求:浏览器在向服务器发送请求数据时,或是服务器在向浏览器发送响应数据时,都必须按照固定的格式进行数据传输
特点:
是一种面向连接的(建立连接之前是需要经过三次握手)、可靠的、基于字节流的传输层通信协议,在数据传输方面更安全
基于请求-响应模型: 一次请求对应一次响应(先请求后响应)
请求和响应是一一对应关系,没有请求,就没有响应
HTTP协议是无状态协议: 对于数据没有记忆能力。每次请求-响应都是独立的
无状态指的是客户端发送HTTP请求给服务端之后,服务端根据请求响应数据,响应完后,不会记录任何信息。
- 缺点: 多次请求间不能共享数据
- 优点: 速度快
HTTP-请求协议:
浏览器和服务器是按照HTTP协议进行数据通信的。
HTTP协议又分为:请求协议和响应协议
- 请求协议:浏览器将数据以请求格式发送到服务器
- 包括:请求行、请求头 、请求体
- 响应协议:服务器将数据以响应格式返回给浏览器
- 包括:响应行 、响应头 、响应体
| 请求方式 | 请求说明 |
|---|---|
| GET | 获取资源。 向特定的资源发出请求。例:http://www.baidu.com/s?wd=itheima |
| POST | 传输实体主体。 向指定资源提交数据进行处理请求(例:上传文件),数据被包含在请求体中。 |

GET请求和POST请求的区别:
| 区别方式 | GET请求 | POST请求 |
|---|---|---|
| 请求参数 | 请求参数在请求行中。 例:/brand/findAll?name=OPPO&status=1 |
请求参数在请求体中 |
| 请求参数长度 | 请求参数长度有限制(浏览器不同限制也不同) | 请求参数长度没有限制 |
| 安全性 | 安全性低。原因:请求参数暴露在浏览器地址栏中。 | 安全性相对高 |
HTTP-响应协议
格式:与HTTP的请求一样,HTTP响应的数据也分为3部分:响应行、响应头 、响应体

响应行(以上图中红色部分):响应数据的第一行。响应行由
协议及版本、响应状态码、状态码描述组成- 协议/版本:HTTP/1.1
- 响应状态码:200
- 状态码描述:OK
响应头(以上图中黄色部分):响应数据的第二行开始。格式为key:value形式
响应体(以上图中绿色部分): 响应数据的最后一部分。存储响应的数据
- 响应体和响应头之间有一个空行隔开(作用:用于标记响应头结束)
响应状态码
| 状态码分类 | 说明 |
|---|---|
| 1xx | 响应中 — 临时状态码。表示请求已经接受,告诉客户端应该继续请求或者如果已经完成则忽略 |
| 2xx | 成功 — 表示请求已经被成功接收,处理已完成 |
| 3xx | 重定向 — 重定向到其它地方,让客户端再发起一个请求以完成整个处理 |
| 4xx | 客户端错误 — 处理发生错误,责任在客户端,如:客户端的请求一个不存在的资源,客户端未被授权,禁止访问等 |
| 5xx | 服务器端错误 — 处理发生错误,责任在服务端,如:服务端抛出异常,路由出错,HTTP版本不支持等 |
HTTP-协议解析-Tomcat
服务器
在网络环境下,根据服务器提供的服务类型不同,可分为:文件服务器,数据库服务器,应用程序服务器,WEB服务器等。
服务器只是一台设备,必须安装服务器软件才能提供相应的服务。
服务器软件
服务器软件:基于ServerSocket编写的程序
- 服务器软件本质是一个运行在服务器设备上的应用程序
- 能够接收客户端请求,并根据请求给客户端响应数据

Web服务器
Web服务器是一个应用程序(软件),对HTTP协议的操作进行封装,使得程序员不必直接对协议进行操作(不用程序员自己写代码去解析http协议规则),让Web开发更加便捷。主要功能是”提供网上信息浏览服务”。
Web服务器是安装在服务器端的一款软件,将来我们把自己写的Web项目部署到Tomcat服务器软件中,当Web服务器软件启动后,部署在Web服务器软件中的页面就可以直接通过浏览器来访问了。
Web服务器软件使用步骤
- 准备静态资源
- 下载安装Web服务器软件
- 将静态资源部署到Web服务器上
- 启动Web服务器使用浏览器访问对应的资源
spring
1 | spring 是一款轻量级的java开发框架,一般指的是spring framework,他是很多模块的集合,包括springboot快速启动,springcloud微服务,spring Data数据库等spring全家桶 |
springboot入门程序解析
起步依赖:创建好springboot工程就会导入的依赖,含有starter的
SpringBootWeb的请求响应
快速入门程序:
基于springboot开发一个web应用,浏览器发起/hello请求时候,给浏览器返回字符串helloworld,

我们在浏览器发起请求,请求了后端web服务器(内置的Tomcat),请求会被部署在Tomcat的Controller接收,然后Controller再给浏览器一个响应helloworld
其实呢,在Tomcat这类web服务器中,是不识别我们自己定义的Controller类的,
Tomcat是一个servlet容器,支持servlet规范的,所以在Tomcat中是可以识别servlet程序的
那我们所编写的XxxController 是如何处理请求的,又与Servlet之间有什么联系呢?
其实呢,在SpringBoot进行web程序开发时,它内置了一个核心的Servlet程序 DispatcherServlet,称之为 核心控制器。 DispatcherServlet 负责接收页面发送的请求,然后根据执行的规则,将请求再转发给后面的请求处理器Controller,请求处理器处理完请求之后,最终再由DispatcherServlet给浏览器响应数据
Servlet
是一种Java编程模型,用于在Web服务器上处理HTTP请求和响应。Servlet充当了Web应用程序的控制器,允许开发者以Java编写服务器端逻辑,以响应客户端的HTTP请求。
请求:Postman
Postman是一款功能强大的网页调试与发送网页HTTP请求的Chrome插件。
可以模拟浏览器向后端服务器发起任何形式(如:get、post)的HTTP请求
使用Postman还可以在发起请求时,携带一些请求参数、请求头等信息
简单参数
在向服务器发起请求时,向服务器传递一些普通的请求数据
后端程序中,两种方式接受传递过来的普通数据
1.原始方式:通过servlet中提供的API:
2.springboot方式:对原始的API进行了封装
1 |
|
注解的作用:用来为代码提供元数据信息的特殊标注,以便在编译,运行,框架扫描,执行特定的操作
在Java中
1 | 编译时注解:作用于编译器,在代码编译时执行特定的操作,例如重写override,就会确保子类正确的覆盖父类的方法 |
在springboot中
1 | 1.依赖注入:@Autowired自动装配bean,当一个类上使用 `@Autowired` 注解时,Spring容器会自动查找并注入满足依赖关系的Bean。减少了手动配置的需求 |
@RequestParam注解:
对于简单参数来讲
请求参数名和controller方法中的形参名不一致时,无法接收到请求数据
那么如果我们开发中,遇到了这种请求参数名和controller方法中的形参名不相同,怎么办?
解决方案:可以使用Spring提供的@RequestParam注解完成映射
1 |
|
实体参数
简单实体对象:将请求参数封装为一个对象,请求参数名称和实体类的属性名称相同
复杂实体对象:
请求参数名与形参对象属性名相同,按照对象层次结构关系即可接收嵌套实体类属性参数。*
数组和集合参数
数组:直接使用数组封装
集合:通过@RequestParam注解绑定参数关系@RequestParam List
日期参数
使用注解@DateTimeFormat(pattern = “yyyy-MM-dd HH:mm:ss”)注解指明其具体格式完成
JSON参数:最常见的前后端数据交互方式
需要使用@Requestbody标识
路径参数
直接在请求的url中传递参数,例如http://localhost:8080/user/1name
@pathParam
1 |
|
@PathVariable注解
作用:从url中提取并且映射到方法参数中的占位符(路径变量)的值
过程:当一个请求到达spring控制器controller时,spring会解析请求的url,并将其中的路径变量与使用注解的参数方法匹配,匹配成功后,将路径变量的值映射到方法参数中,供方法使用
@Requestbody注解
作用:用于将HTTP请求的具体内容(通常为JSON或者xml的数据)映射到JAVA对象上
过程:当一个HTTP POST请求到达Spring控制器方法时,Spring会从请求体中提取数据,然后使用 @RequestBody 注解的方法参数的类型来进行反序列化,将请求体中的数据映射为Java对象。
@RequestParam注解
作用:用于从HTTP请求中获取参数的值,并且将其绑定到方法参数上,供方法使用
总结

响应
请求响应模式:有请求就有响应
Controller程序除了接受请求外,还能进行响应,通过@ResponseBody响应,而@ResponseBody又是集成在@ResController中
@RestController = @Controller + @ResponseBody
@ResponseBody注解
- 类型:方法注解、类注解
- 位置:书写在Controller方法上或类上
- 作用:将方法返回值直接响应给浏览器
- 如果返回值类型是实体对象/集合,将会转换为JSON格式后在响应给浏览器
分层解耦合
三层架构:开发程序时候尽可能让每一个接口、类、方法的职责更单一些(单一职责原则)。
单一职责原则:一个类或一个方法,就只做一件事情,只管一块功能。
这样就可以让类、接口、方法的复杂度更低,可读性更强,扩展性更好,也更利用后期的维护。
基于三层架构的执行流程:

前端发起请求,由Controller层接受(Controller 响应数据给前端)
Controller层,调用Service层来进行逻辑处理,把处理结果返回给Controller层
Service层:在逻辑处理的过程中调用Dao层(逻辑处理的过程中需要数据从Dao层中获取)
Dao层操作文件中的数据(Dao层中拿到的数据会返回给Service层)
由于数据访问的对象,可能是文件,数据库,别人接口获取到的数据,
所以要先定义一个Dao的接口,再用不同的类去实现这个接口,重写接口中的方法
(这里本质上就是接口多态的实现,传入一个接口类型的实现类对象,根据不同实现类对象调用不同实现类里重写的方法)
分层解耦
内聚:软件中各个模块内部的功能联系
耦合:衡量软件中各层、模块之间的依赖,关联程度
软件设计原则:高内聚低耦合
高内聚指的是:一个模块中各个元素之间的联系的紧密程度,如果各个元素(语句、程序段)之间的联系程度越高,则内聚性越高,即 “高内聚”。
低耦合指的是:软件中各个层、模块之间的依赖关联程序越低越好。
需要用到spring的核心概念
控制反转:IOC,
对象的创建控制权由程序自身,转移到外部容器
@Component //将当前对象交给IOC容器管理,成为IOC容器的bean
依赖注入:DI,
容器为应用程序提供运行时,所依赖的资源,称依赖注入
@Autowired//运行时从IOC容器中获取该类型的对象,并且赋值给变量
1 | //将当前对象交给IOC容器管理,成为IOC容器的bean |
IOC 详解
bean对象的声明:Spring框架为了更好的标识web应用程序开发当中,bean对象到底归属于哪一层,又提供了@Component的衍生注解:
- @Controller (标注在控制层类上)
- @Service (标注在业务层类上)
- @Repository (标注在数据访问层类上)
| 注解 | 说明 | 位置 |
|---|---|---|
| @Controller | @Component的衍生注解 | 标注在控制器类上 |
| @Service | @Component的衍生注解 | 标注在业务类上 |
| @Repository | @Component的衍生注解 | 标注在数据访问类上(由于与mybatis整合,用的少) |
| @Component | 声明bean的基础注解 | 不属于以上三类时,用此注解 |
组件扫描
bean对象要生效,还需要被组件扫描
需要被组件@ComponentScan扫描,被集成在@SpringbootApplication中,默认扫描范围是SpringBoot启动类所在的包及其子包
依赖注入详解DI:
使用了@Autowired这个注解,完成了依赖注入的操作,而这个Autowired翻译过来叫:自动装配。
@Autowired注解,默认是按照类型进行自动装配的(去IOC容器中找某个类型的对象,然后完成注入操作)
举例:在Controller运行的时候,就要到IOC容器当中去查找service类型的对象,而我们的IOC容器中刚好有service对象,所以,就找到这个类型的对象完成注入操作
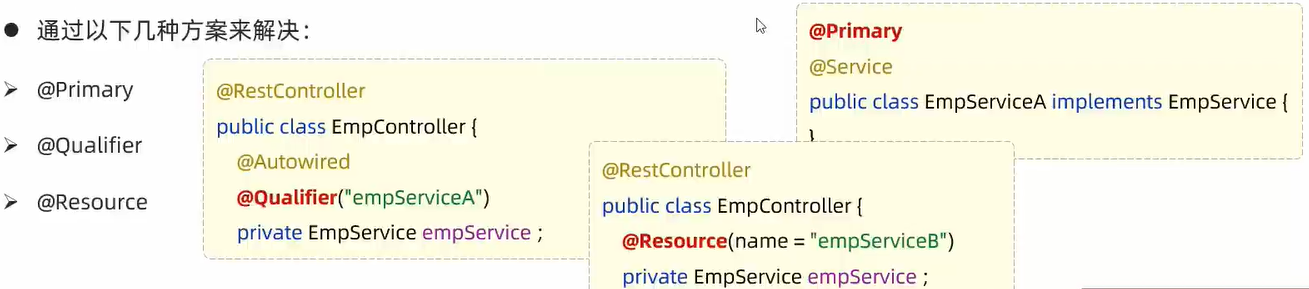
IOC容器里,存在多个相同类型的bean对象,会报错,需要添加注解指明当前生效的bean类
@Primary:当存在多个相同类型的Bean注入时,加上@Primary注解,来确定默认的实现。
@Qualifier:指定当前要注入的bean对象。 在@Qualifier的value属性中,指定注入的bean的名称。
@Resource:是按照bean的名称进行注入。通过name属性指定要注入的bean的名称。
数据库
概述:持久化,把数据保存到可掉电式存储设备中供以后使用
数据库: database DB:文件系统,保存了一系列数据
DBMS:数据库管理系统:操作和管理数据库的大型软件
关系型数据库:行列形式存储
非关系型:数据以对象的形式存储在数据库中
键值型数据库:key-value形式
搜索引擎数据库:倒排索引
针对于数据库来说,主要包括三个阶段:
- 数据库设计阶段
- 参照页面原型以及需求文档设计数据库表结构
- 数据库操作阶段
- 根据业务功能的实现,编写SQL语句对数据表中的数据进行增删改查操作
- 数据库优化阶段
- 通过数据库的优化来提高数据库的访问性能。优化手段:索引、SQL优化、分库分表等
SQL:
结构化查询语言 structured Query Language
- SQL的分类
DDL:数据定义语言 ,CREATE \ ALTER \ DROP \ RENAME \ TRUNCATE
DML:数据操作语言 INSERT \ DELETE \ UPDATE \ SELECT \
DCL:数据控制语言 COMMIT \ ROLLBACK \ SAVEPOINT \ GRANT \ REVOKE
链接:localhost 端口:3306 用户名:user 密码:123456
表操作:
案例:创建一个表
1 | create table 表名( |
1 | create table tb_user ( |
约束:
| 约束 | 描述 | 关键字 |
|---|---|---|
| 非空约束 | 限制该字段值不能为null | not null |
| 唯一约束 | 保证字段的所有数据都是唯一、不重复的 | unique |
| 主键约束 | 主键是一行数据的唯一标识,要求非空且唯一 | primary key |
| 默认约束 | 保存数据时,如果未指定该字段值,则采用默认值 | default |
| 外键约束 | 让两张表的数据建立连接,保证数据的一致性和完整性 | foreign key |
1 | create table tb_user ( |
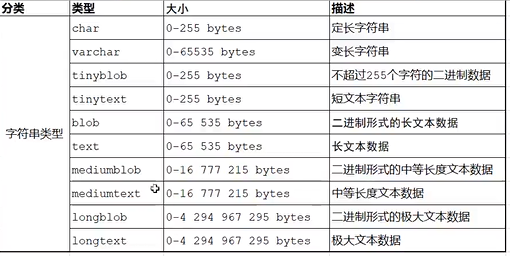
数据类型:数值类型,字符串类型,日期和时间类型
数值类型

字符串类型
日期时间类型

设计表流程
通过上面的案例,我们明白了,设计一张表,基本的流程如下:
阅读页面原型及需求文档
基于页面原则和需求文档,确定原型字段(类型、长度限制、约束)
再增加表设计所需要的业务基础字段(id主键、插入时间、修改时间)

说明:
create_time:记录的是当前这条数据插入的时间。
update_time:记录当前这条数据最后更新的时间。

或者直接用图形化界面操作完成
数据库操作:DML
增加:insert
1 | insert into 表名 (字段名1, 字段名2) values (值1, 值2); |
案例1:向tb_emp表的username、name、gender字段插入数据
1 | -- 因为设计表时create_time, update_time两个字段不能为NULL,所以也做为要插入的字段 |
案例2:向tb_emp表的所有字段插入数据
1 | insert into tb_emp(id, username, password, name, gender, image, job, entrydate, create_time, update_time) |
案例3:批量向tb_emp表的username、name、gender字段插入数据
1 | insert into tb_emp(username, name, gender, create_time, update_time) |
修改:update
1 | update 表名 set 字段名1 = 值1 , 字段名2 = 值2 , .... [where 条件] ; |
删除:delete
1 | delete from 表名 [where 条件] ; |
数据库操作:DQL
select
1 | select...from(join on)...where...group by...having...order by...limit... |
sql语句的底层执行过程
在SQL语句中,执行顺序通常遵循以下规则:
FROM子句:首先执行FROM子句,以确定要查询的表和列。
FROM…(LEFT/RIGHT)JOIN…ON 多表的链接条件
WHERE子句:如果存在WHERE子句,则会先执行WHERE子句,以过滤出符合条件的行。
GROUP BY子句:如果存在GROUP BY子句,则会先执行GROUP BY子句,以将结果按照指定的列进行分组。
HAVING子句:如果存在HAVING子句,则会先执行HAVING子句,以过滤出满足聚合函数条件的组。
ORDER BY 。。。
LIMIT。。。
SELECT子句:最后执行SELECT子句,以选择需要返回的列。
具体见数据库学习笔记
where having
where与having区别(面试题)
- 执行时机不同:where是分组之前进行过滤,不满足where条件,不参与分组;而having是分组之后对结果进行过滤。
- 判断条件不同:where不能对聚合函数进行判断,而having可以。
外键约束
1 | -- 创建表时指定 |
多表设计
一对多
一对一
多对多
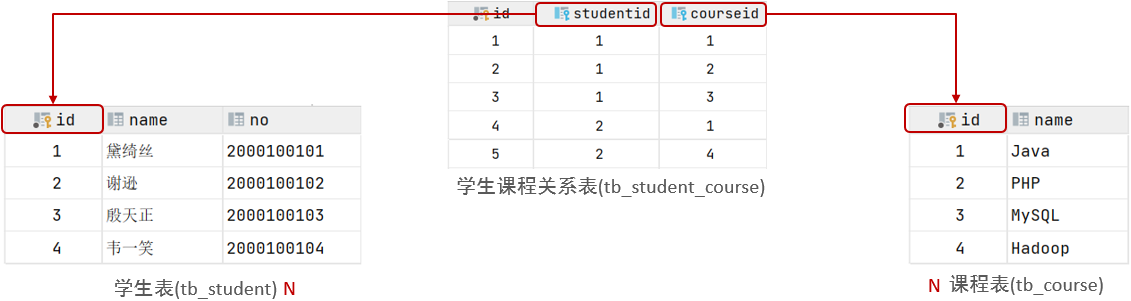
多对多的关系在开发中属于也比较常见的。比如:学生和老师的关系,一个学生可以有多个授课老师,一个授课老师也可以有多个学生。在比如:学生和课程的关系,一个学生可以选修多门课程,一个课程也可以供多个学生选修。
关系:一个学生可以选修多门课程,一门课程也可以供多个学生选择
实现关系:建立第三张中间表,中间表至少包含两个外键,分别关联两方主键
多表查询:
1 | select 表1字段,表2字段 from 表1,表2 where 表1.字段=表2.字段 |
多表查询的分类:
1.等值连接 非等值连接
2.自连接 非自连接
3.内连接 外连接
1.等值连接 非等值连接的例子
1 | SELECT e.last_name,e.salary,j.grade_level |
2.自连接的例子:在同一张表里
查询员工ID,员工姓名,及其管理者的ID和姓名
1 | SELECT e1.employee_id,e1.last_name,e2.employee_id,e2.last_name |
3.内连接,外连接
内连接:结果集中,不包括一个表与另一个表不匹配的行
外连接:结果集中,出了匹配的行,还查询左表或者右表中不匹配的行
外连接的分类:左外连接,右外连接,全满外连接

单行函数,聚合函数
子查询
单行子查询:查找出的只有一行数据,使用常规的比较符,=,<,>,
多行子查询,查找出多行数据
多行比较的操作符:
IN:等于列表中任意一个
ANY:某一个值比较
ALL:所有值比较
Some:any的别名
事物
事物:是一组操作的集合,它是一个不可分割的工作单位,事物会把所有的操作试做一个整体,一起向系统提交或者撤销操作请求操作,要么同事成功,要么同时失败。
一个业务要发送多条SQL语句给数据库执行。需要将多次访问数据库的操作视为一个整体来执行,要么所有的SQL语句全部执行成功。如果其中有一条SQL语句失败,就进行事务的回滚,所有的SQL语句全部执行失败。
使用事务控制删除部门和删除该部门下的员工的操作:
1 | -- 开启事务 |
- 上述的这组SQL语句,如果如果执行成功,则提交事务
1 | -- 提交事务 (成功时执行) |
- 上述的这组SQL语句,如果如果执行失败,则回滚事务
1 | -- 回滚事务 (出错时执行) |
事物的四大特性
原子性:事物是不可分割的最小单元,要么全部成功,要么全部失败
一致性:事物完成时,必须使得所有的数据状态都保持一致
隔离性:数据库系统提供隔离机制,保证事物在不受外部并发操作影响的独立环境下运行
持久性:事物一旦回滚,它对数据库中的数据的改变是永久的
索引:index:
帮助数据库高效获取数据的数据结构
无索引:全表扫描
有索引: 树形结构,大大减少查询时间
优点:大大提高查询效率
缺点:索引占用存储空间,同时降低,插入,删除,更新效率,要维护索引
MySQL数据库支持的索引结构有很多,如:Hash索引、B+Tree索引、Full-Text索引等。
我们平常所说的索引,如果没有特别指明,都是指默认的 B+Tree 结构组织的索引。
二叉树:左边子节点比父节点小,右边子节点比父节点大
红黑树:是一种平衡二叉树
B+Tree:多路平衡搜索树
创建索引
1 | create [ unique ] index 索引名 on 表名 (字段名,... ) ; |
查看索引
1 | show index from 表名; |
删除索引
1 | drop index 索引名 on 表名; |
注意事项:
- 主键字段,在建表时,会自动创建主键索引
- 添加唯一约束时,数据库实际上会添加唯一索引
自己做SQL时候的一些训练
1 | SELECT employee_id ,last_name,salary |
1 | SELECT * from employees |
MyBatis
mybatis是一款优秀的dao持久层框架,使用Java程序操作数据库
使用mybatis操作数据库,就是在mybatis中编写查询代码,发送给数据库执行,数据库执行后,会把数据执行的查询结果,使用实体类封装起来(一行记录对应一个实体类对象)
使用实体类定义对象的属性的时候,要用包装类,因为数据库中的数据存在为空的情况,字段会返回值null,int类型的默认数值为0,包装类Integer 的默认类型为null
mybatis快速入门
1.创建springboot工程,数据表user,实体类User
2.引入mybatis的相关依赖,mybatis Framework框架,MySQL Driver配置信息
在resource中的application中里配置数据库的驱动,url,用户名,密码等
3.定义接口,@Mapper ,注解用于运行时自动生成实现类对象,交给spring的IOC容器管理
@select,编写SQL语句
4,单元测试:通过依赖注入@Autowired,注入mapper接口,再调用mapper接口的list方法,输出所查询到的数据
JDBC:Java DataBase Connectivity
使用Java操作数据库的一套api,一套操作所有关系型数据库的规范,即接口。各个数据库厂商去实现这套接口
Mybatis框架,就是对原始的JDBC程序的封装。
原始jdbc程序的步骤:
1.注册驱动
2.获取链接对象
3.执行SQL语句,返回执行结果
4.处理执行结果
5.释放资源
缺点:
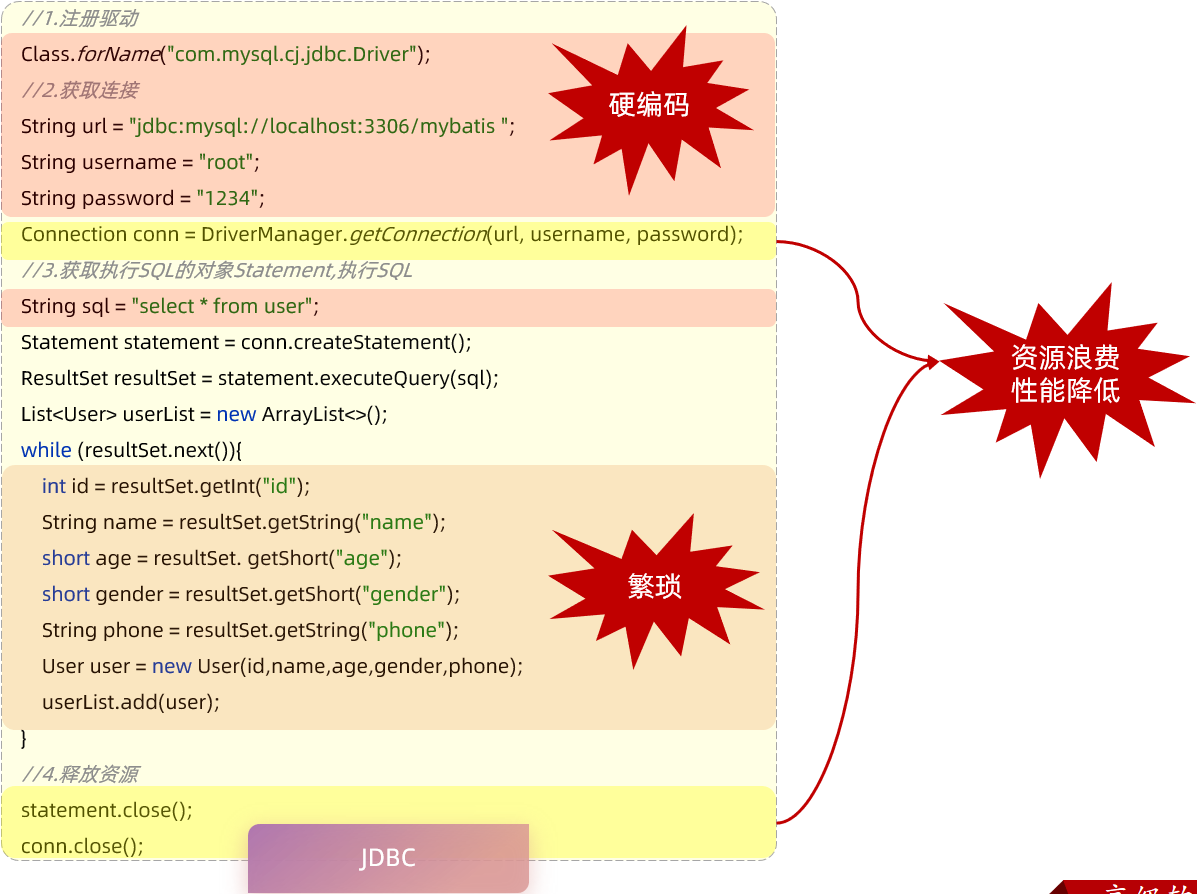
mybatis中对这些问题的解决
1.数据库链接的四要素,(驱动,链接,用户名,密码),都配置在springboot的默认配置文件中,
2.查俊结果以及解析的封装,都由mybatis自动完成映射封装,我们无需关注
3.在mybatis中使用了数据库的连接池技术,从而避免了频繁的创建链接,销毁链接而带来的资源浪费
数据库连接池
没有使用数据库连接池:
客户端执行SQL语句,要先创建一个链接对象,在执行SQL,执行完后要释放,每次都要,频繁的重复销毁会比较耗费计算机的性能
数据库连接池是个容器,负责分配管理数据库的链接Connection
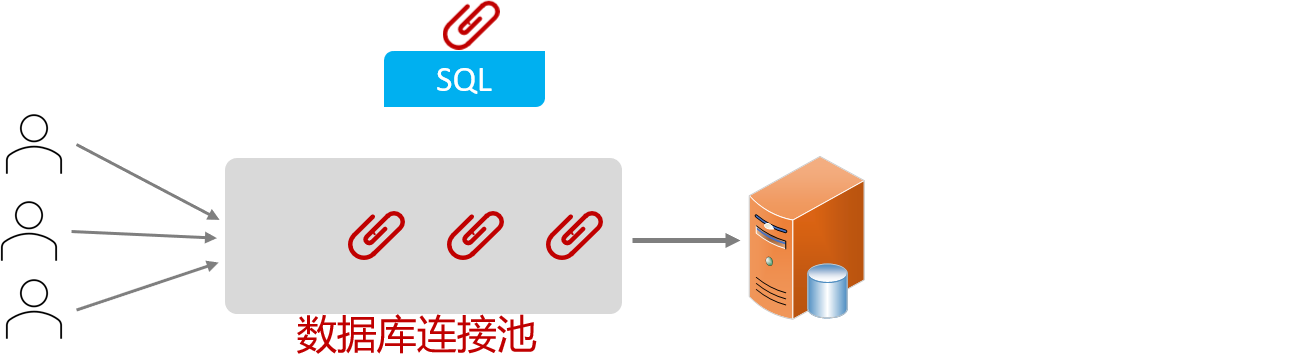
- 程序在启动时,会在数据库连接池(容器)中,创建一定数量的Connection对象
允许应用程序重复使用一个现有的数据库连接,而不是再重新建立一个
- 客户端在执行SQL时,先从连接池中获取一个Connection对象,然后在执行SQL语句,SQL语句执行完之后,释放Connection时就会把Connection对象归还给连接池(Connection对象可以复用)
释放空闲时间超过最大空闲时间的连接,来避免因为没有释放连接而引起的数据库连接遗漏
- 客户端获取到Connection对象了,但是Connection对象并没有去访问数据库(处于空闲),数据库连接池发现Connection对象的空闲时间 > 连接池中预设的最大空闲时间,此时数据库连接池就会自动释放掉这个连接对象
连接池的好处:
资源重用
提升系统的响应速度
避免数据库的链接泄露
产品:常用的数据库连接池
Hikari:追光者,springboot默认的连接池
Druid:德鲁伊,阿里开源的数据库连接池
修改连接池的方法:直接引入依赖即可
1 | <dependency> |
lombok
是一个实用的JAVA类库,通过注解的方式自动生成,构造器,getter,setter,hashcode,toString等方法,并且可以自动化生成日志变量,简化JAVA开发,提高效率
| 注解 | 作用 |
|---|---|
| @Getter/@Setter | 为所有的属性提供get/set方法 |
| @ToString | 会给类自动生成易阅读的 toString 方法 |
| @EqualsAndHashCode | 根据类所拥有的非静态字段自动重写 equals 方法和 hashCode 方法 |
| @Data | 提供了更综合的生成代码功能(@Getter + @Setter + @ToString + @EqualsAndHashCode) |
| @NoArgsConstructor | 为实体类生成无参的构造器方法 |
| @AllArgsConstructor | 为实体类生成除了static修饰的字段之外带有各参数的构造器方法。 |
使用:
1.引入依赖
1 | <!-- 在springboot的父工程中,已经集成了lombok并指定了版本号,故当前引入依赖时不需要指定version --> |
2.在实体类上添加注解
Mybatis的基础操作
日志输入
打开application.properties文件,配置文件,配置一下属性
1 | #指定mybatis输出日志的位置, 输出控制台 |
1.删除
1 | @Mapper |
#{id} 是一个占位符,表示要传递给SQL语句的参数值。这个占位符会在实际执行时被具体的参数值替代
预编译SQL
优势:1.性能更高 2.更安全:防止SQL注入
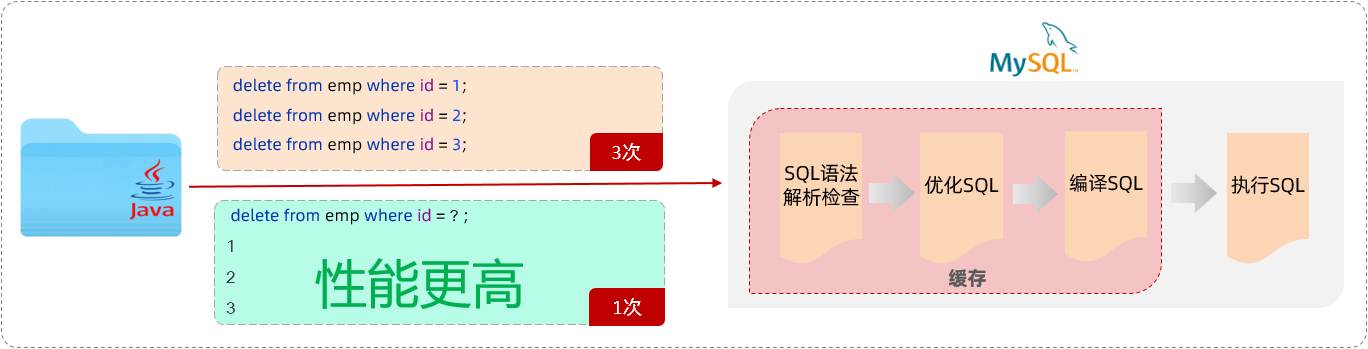
普通的SQL执行过程:解析-优化-编译-执行
预编译SQL:编译一次后将SQL语句缓存起来,后续再执行时,不会再次编译,只是输入的参数不同
SQL注入
原因:由于没有对用户输入内容进行充分检查,而SQL又是字符串拼接方式而成,在用户输入参数时,在参数中添加一些SQL关键字,达到改变SQL运行结果的目的,从而完成恶意攻击。
举例:一个登录管理系统中,有账户名和密码字段,而判断是否为用户登陆就是,查询用户名和密码字段是否与数据库中的匹配
1 | select count(*) from emp where username = '' and password = '' |
SQL注入:任意username ,password为 ‘ or ‘1’=’1
1 | select count(*) from emp where username = 'd' and password = '' or '1'='1' |
用户在页面提交数据的时候人为的添加一些特殊字符,使得sql语句的结构发生了变化,最终可以在没有用户名或者密码的情况下进行登录。
参数占位符
在mybatis中提供的参数占位符有两种:${},#{}
#{…}
- 执行SQL时,会将#{…}替换为?,生成预编译SQL,会自动设置参数值
- 使用时机:参数传递,都使用#{…}
${…}
- 拼接SQL。直接将参数拼接在SQL语句中,存在SQL注入问题
- 使用时机:如果对表名、列表进行动态设置时使用
用like等模糊查询时,需要使用MySQL提供的字符串拼接函数:concat(‘%’ , ‘关键字’ , ‘%’),以防止SQL注入问题
在上面我们所编写的条件查询功能中,我们需要保证接口中方法的形参名和SQL语句中的参数占位符名相同。
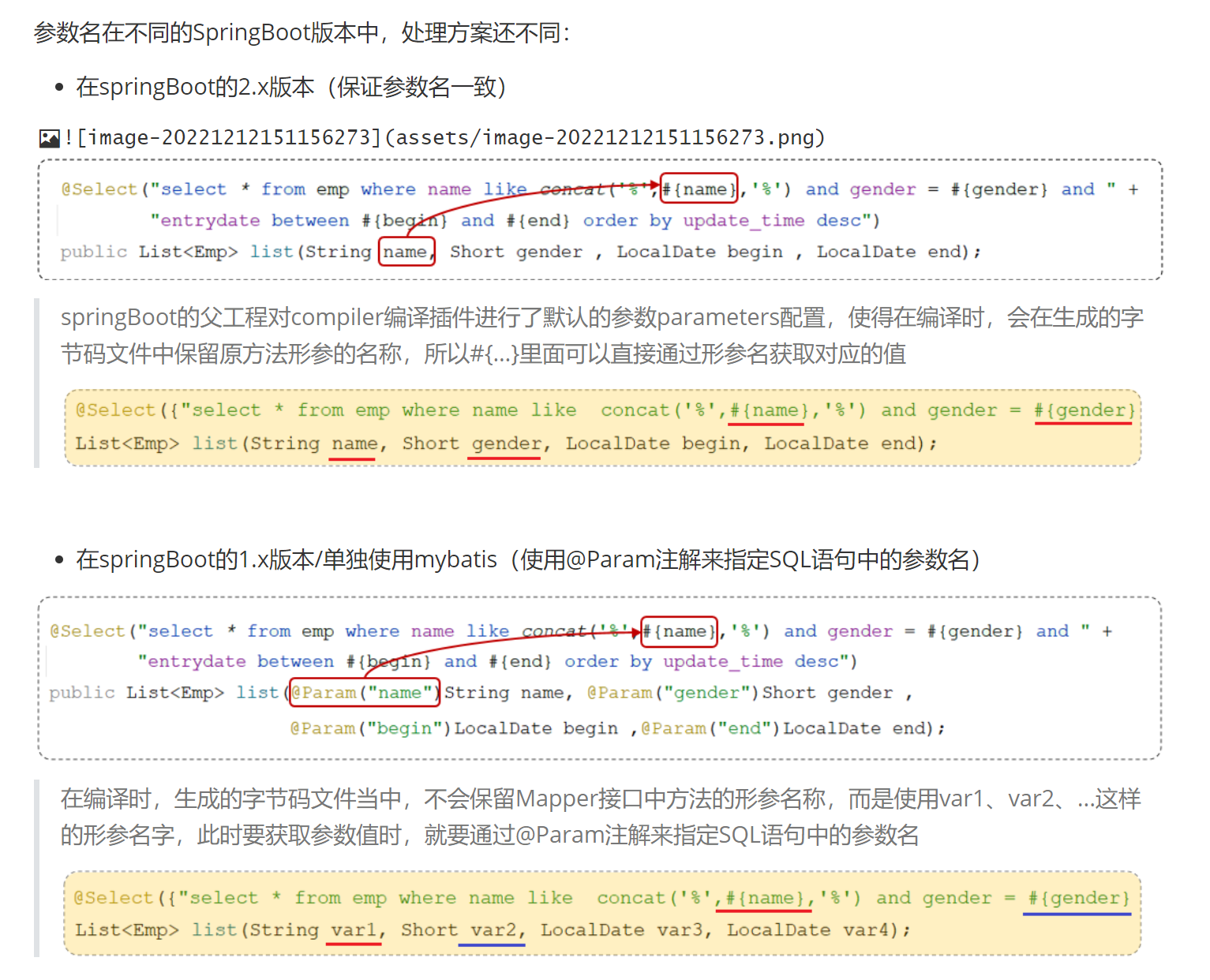
MyBatista的XML配置文件
使用MyBatista注解的方式,主要是完成一些简单的增删改查功能
如果需要实现复杂的SQL功能,建议使用XML配置映射,将SQL语句写在XML配置文件中
在MyBatis中使用XML需要符合一定的规范
1.XML映射文件名称与Mapper接口的名称一致,并且将XML映射文件和Mapper接口放置在相同包下(同包同名) 一个接口对应一个相同的XML文件
2.XML映射文件的namespace属性与Mapper接口全限定名一样
3.XML映射文件中SQL语句的id与Mapper接口的方法名称一样,并且保持返回类型一致
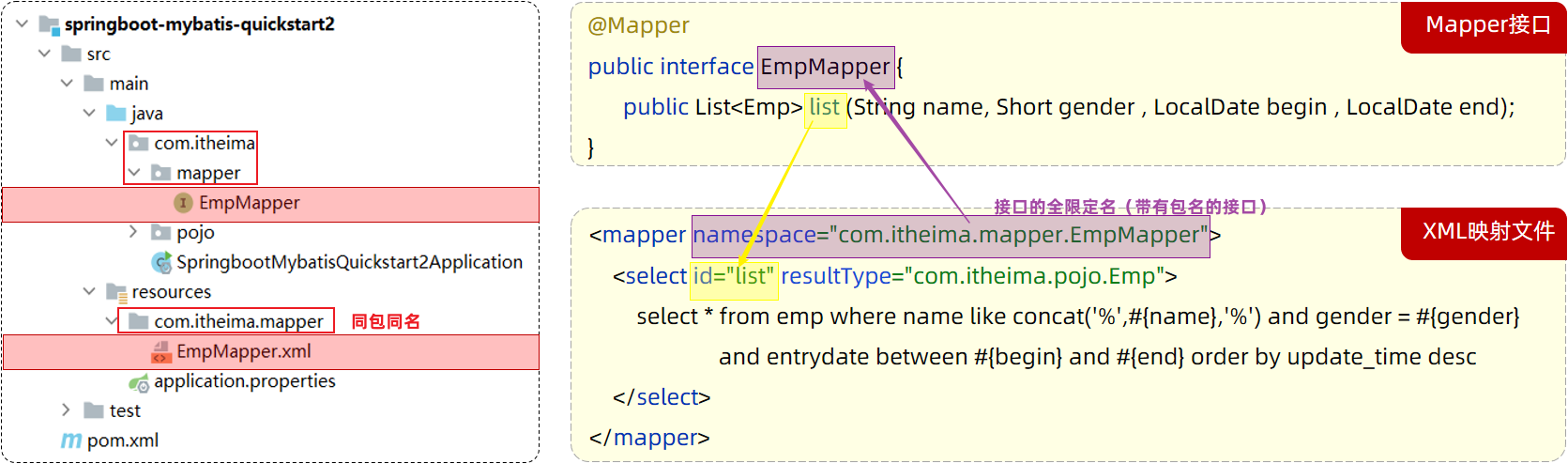
配置:XML映射文件中sql语句的id与Mapper接口中的方法名一致,并保持返回类型一致
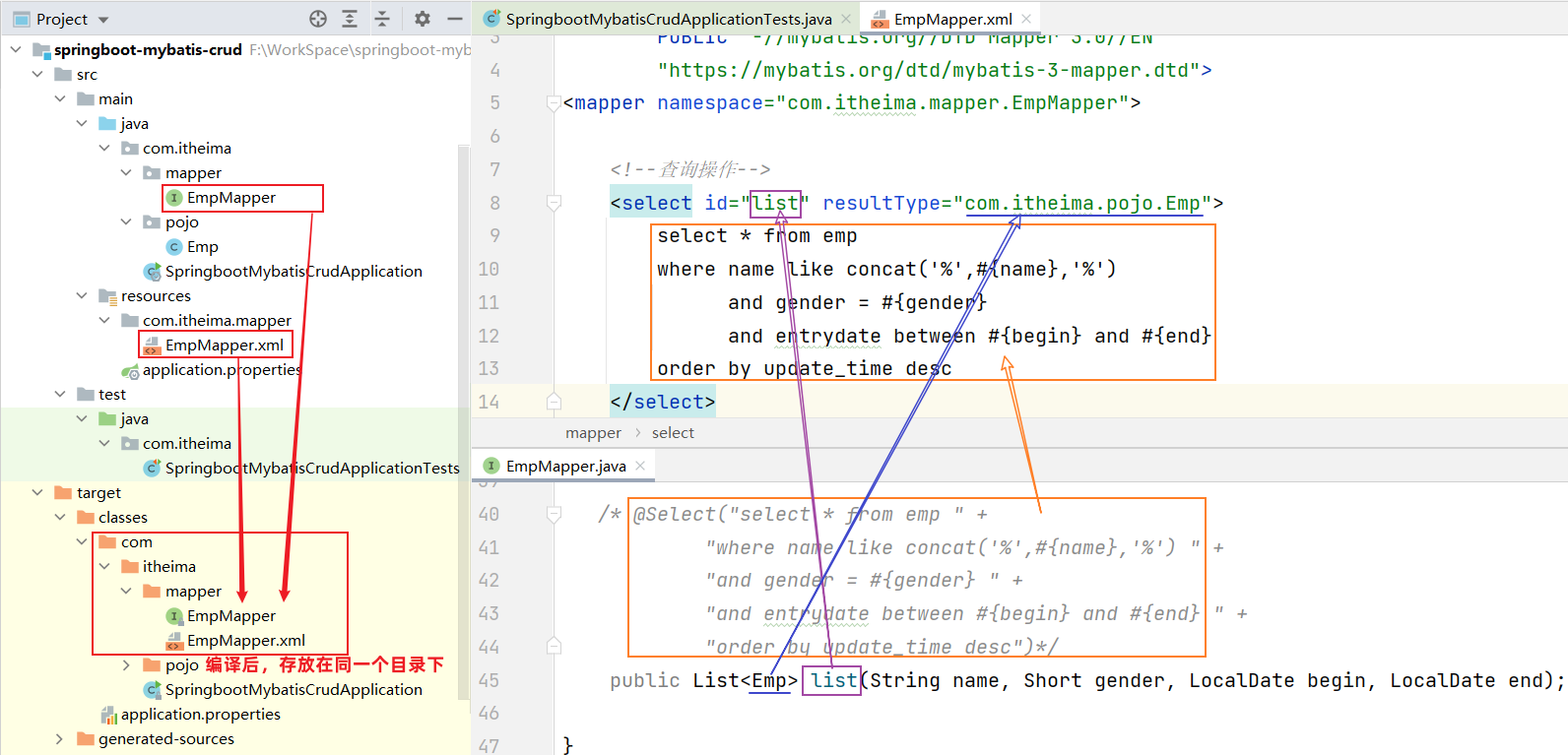
Mybatis动态SQL
SQL语句会随着用户的输入或者外部的条件变化而变化,称为:动态SQL
动态SQL-if
<where>只会在子元素有内容的情况下才插入where子句,而且会自动去除子句的开头的AND或OR
1 | <select id="list" resultType="com.itheima.pojo.Emp"> |
1 | <update id="update"> |
1 | <!--批量删除员工(1,2,3) |
<sql>:定义可重用的SQL片段
案例的开发规范与开发流程
开发规范-REST
在前后端进行交互的时候,要基于当前主流的的REST风格的API进行交互
REST是一种风格,REST(Representational State Transfer),表述性状态转换,它是一种软件架构风格。
传统的url风格如下:
1 | http://localhost:8080/user/getById?id=1 GET:查询id为1的用户 |
基于REST风格的URL如下:
1 | http://localhost:8080/users/1 GET:查询id为1的用户 |
总结:通过url定位要操作的资源,通过HTTP请求方式来描述具体的操作
GET:查询
POST:新增
PUT:修改
DELETE:删除
开发规范-统一响应流程
在使用前后端工程交互的时候,统一使用响应结果Result
1 | package com.itheima.pojo; |
开发流程
查看页面原型明确需求–>阅读接口文档–>思路分析–>接口开发–>接口测试–>前后端联调
基本上就是围绕接口文档做开发,要用到spring中的很多注解
| 10月7日 | 复习相关注解 | ||||||
|---|---|---|---|---|---|---|---|
| @Pathvarible | 将路径url中提取参数并映射到方法参数中 | ||||||
| @RequestBody | 将HTTP请求的具体内容,JSON或者XML | 映射到Java对象上 | |||||
| 10月8日 | 后端按照接口的实现流程 | ||||||
| Controller控制层 | @RequestMapping请求路径 @RequestController控制器 @SLf4j自动定义日志记录对象log | @Autowired依赖注入 deptService对象 @XXXMapping限定请求方式 | 调用deptService.函数() | ||||
| Service逻辑处理层 | Service接口:定义接口方法 Service实现类:重写+逻辑处理 | @Autowired依赖注入 deptMapper对象 | 调用deptMapper.函数() | ||||
| Dao数据访问层 | @Mapper注解: | 表示mybatis映射的接口 | 定义数据库操作的方法 | ||||
| 10月9日 | 根据接口文档的实现流程 | 请求路径:url 请求方式:get set put 请求参数;json | @RequestMapping/@PathVarible @GetMapping @RequestBody | ||||
| 10月10日 | 分页查询插件PageHelper | PageHelper.startPage()设置分页参数 | 将查询结果强转为Page类型 | 调用page方法,getTotalgetResult | |||
| @RequestParam | defaultvalue,如果没有,设置默认值 | ||||||
写了份表格记录一下
大体的开发流程就是
1.根据接口文档确定是什么请求,一般是请求路径和请求方式
请求路径就是/emp/upload等等,请求方式:POST,GET,DELETE,等等
判断是否有路径参数或者请求参数等
2.在控制层,用XXXXMapping接受路径/emp这些,定义一个类型为Result的返回函数,去接受参数
如果请求传递的是路径参数,就用注解@PathVariable接受
如果请求参数是JSON格式的,就需要自己定一个对象,对象的私有属性包含这些,必须同名称,然后用注解
@RequestBody接受,将请求参数封装到实体类的私有属性中,再去调用
3.在控制层用@AutoWired自动注入service层的接口对象,调用service接口层中声明的方法,
定义业务实现类serviceImpl,具体实现这些方法,做一些逻辑处理,并且在类中,自动注入mybatis层的对象
4.在数据控制层就是Mybatis层,用注解@Mapper,这里主要是一些调用数据库的操作
用注解@Select,@delete等等,注解地下声明一个方法,用于接受查询返回的值
或者在resource层中定义xml配置文件,xml配置文件的位置定义要有讲究,在resource层下,要与mapper层的包名类名相同,在xml配置文件中定义动态查询语句
1 |
|
@RequestParam(defaultValue = "1") Integer page:这是一个查询参数,用于指定页码,默认值是 1。@RequestParam 用于从请求中获取名为 page 的参数值。如果请求中没有 page 参数,它将使用默认值 1。
在 Spring MVC 中,默认情况下,如果方法参数的名称与请求中的查询参数名称匹配,Spring 将自动将请求参数值绑定到方法参数,无需显式使用 @RequestParam 注解。这意味着当客户端发送一个请求,其中包含名为 name 和 gender 的查询参数时,Spring 将自动将它们绑定到方法的 name 和 gender 参数上。
文件上传功能
1.前端程序,定义form表单
我们先来看看在前端程序中要完成哪些代码:
1 | <form action="/upload" method="post" enctype="multipart/form-data"> |
上传文件的原始form表单,要求表单必须具备以下三点(上传文件页面三要素):
表单必须有file域,用于选择要上传的文件
1
<input type="file" name="image"/>
表单提交方式必须为POST
通常上传的文件会比较大,所以需要使用 POST 提交方式
表单的编码类型enctype必须要设置为:multipart/form-data
普通默认的编码格式是不适合传输大型的二进制数据的,所以在文件上传时,表单的编码格式必须设置为multipart/form-data
2.后端程序
在服务端定义一个Controller用于文件的上传,在controller中定义一个方法,来处理/upload请求
在定义的方法中接收提交过来的数据(形参名称和请求参数名称保持一致)不一样用@RequestParam
spring中提供了一个API:MultipartFile image 接收文件
MultipartFile 常见方法:
- String getOriginalFilename(); //获取原始文件名
- void transferTo(File dest); //将接收的文件转存到磁盘文件中
- long getSize(); //获取文件的大小,单位:字节
- byte[] getBytes(); //获取文件内容的字节数组
- InputStream getInputStream(); //获取接收到的文件内容的输入流
用image.XXX调用即可
并且使用UUID获取随机文件名称,保证每次上传时候的文件名称都是唯一的
1 |
|
以上只是将上传的文件保存到本地
上传到阿里云OSS(Object Storage Service)
注册:获得阿里云的AccessKey,bucketname等信息
参照官方实例文档的SDK
在Maven项目中使用OSS的SDK,只需要pom文件中添加相应的pom依赖即可
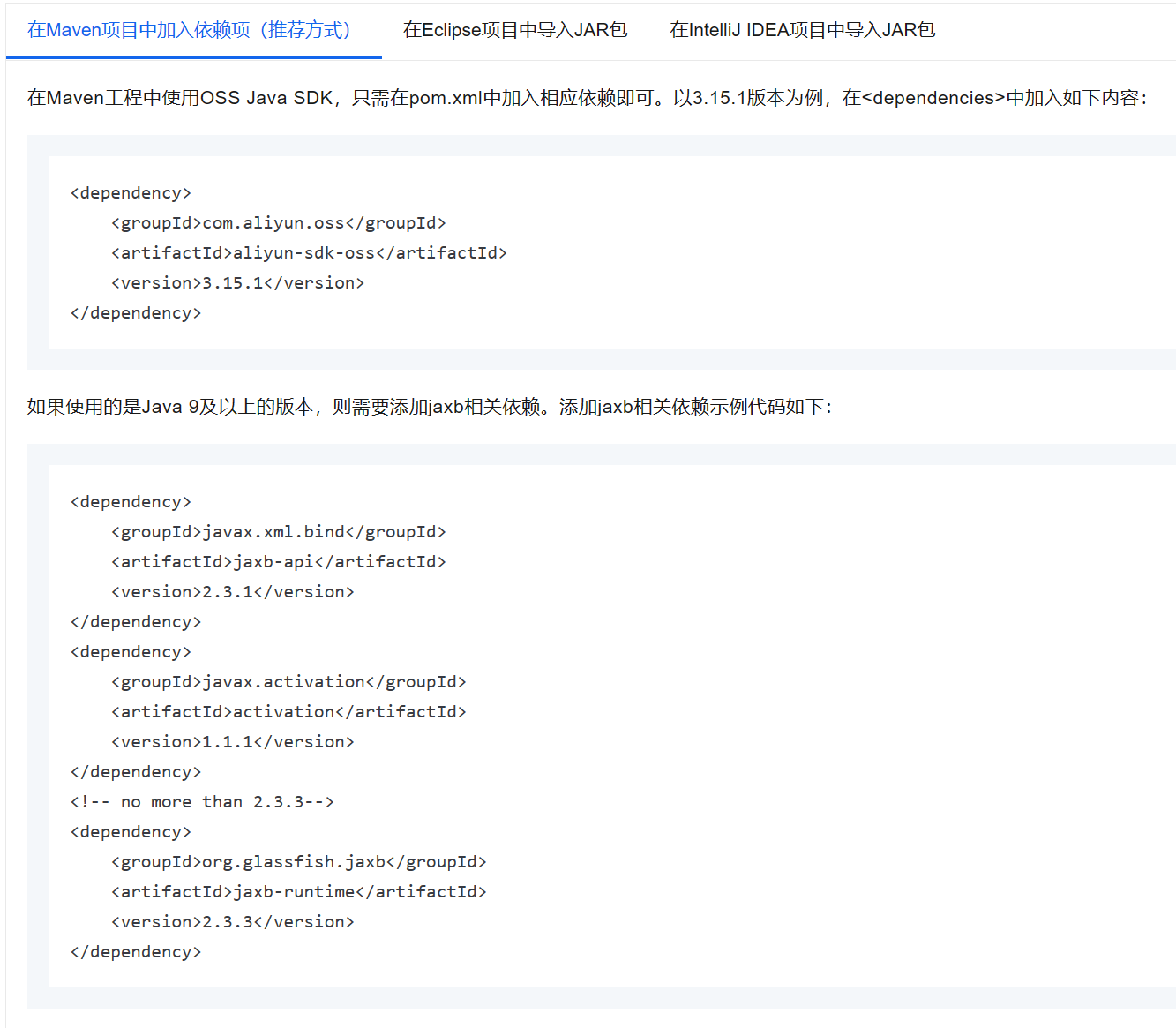
导入依赖后,修改官方参考文档,调用oss中的相关函数,实现文件的上传
使用唯一的UUID确保上传的文件名称唯一
1 | import com.aliyun.oss.OSS; |
最后返回的url就是图片的地址,例如:
https://web-fangyuan.oss-cn-hangzhou.aliyuncs.com/01b43569-4c97-4efe-8e0a-7631044b4ac1.jpg
用网址打开会直接显示下载,在前端的页面就会直接渲染出来
配置文件
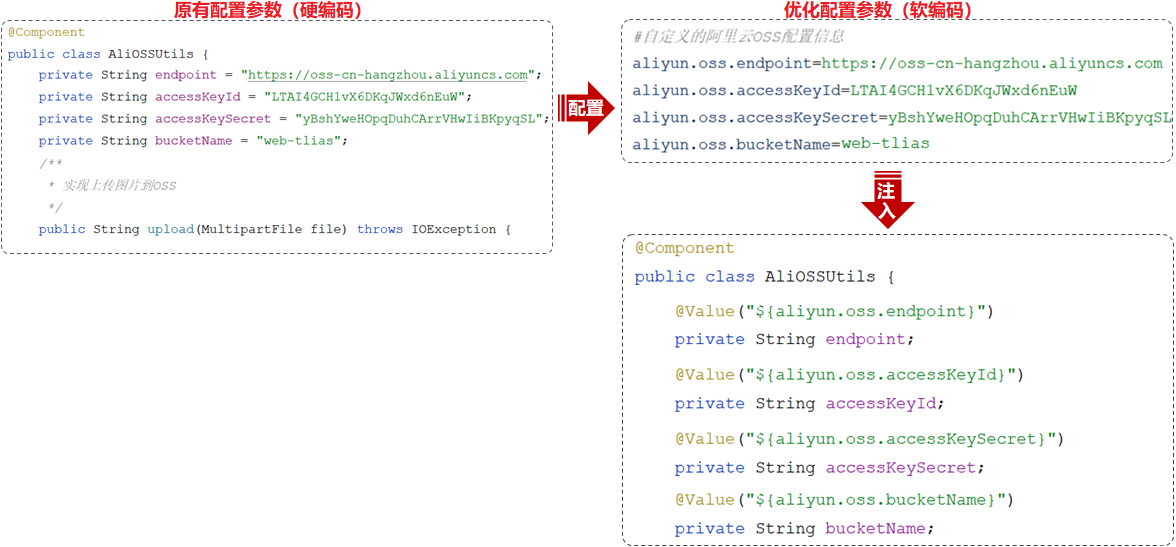
上述阿里云的配置信息写死在了代码中(硬编码)
缺点:在源码中重新改动,要重新编译,配置参数过于分散,不便于集中维护和管理
解决方法1:在application.properties中定义配置信息,再使用注解@Value注入
@Value 注解通常用于外部配置的属性注入,具体用法为: @Value(“${配置文件中的key}”)
yml配置文件

简单的了解过springboot所支持的配置文件,以及不同类型配置文件之间的优缺点之后,接下来我们就来了解下yml配置文件的基本语法:
- 大小写敏感
- 数值前边必须有空格,作为分隔符
- 使用缩进表示层级关系,缩进时,不允许使用Tab键,只能用空格(idea中会自动将Tab转换为空格)
- 缩进的空格数目不重要,只要相同层级的元素左侧对齐即可
#表示注释,从这个字符一直到行尾,都会被解析器忽略

了解完yml格式配置文件的基本语法之后,接下来我们再来看下yml文件中常见的数据格式。在这里我们主要介绍最为常见的两类:
- 定义对象或Map集合
- 定义数组、list或set集合
对象/Map集合
1 | user: |
数组/List/Set集合
1 | hobby: |
@ConfigurationProperties(prefix = “aliyun.oss”)
Spring提供的简化方式套路:
需要创建一个实现类,且实体类中的属性名和配置文件当中key的名字必须要一致
比如:配置文件当中叫endpoints,实体类当中的属性也得叫endpoints,另外实体类当中的属性还需要提供 getter / setter方法
需要将实体类交给Spring的IOC容器管理,成为IOC容器当中的bean对象@Compoent
在实体类上添加
@ConfigurationProperties注解,并通过perfect属性来指定配置参数项的前缀直接@Autowired自动注入bean对象,调用get方法获取到属性值即可
分
登录认证:
新建LoginController控制层,service层和mapper,因为是底层校验员工的数据,所以还是用员工emp层的即可
select * from emp where userame = #{} and pasword = #{}
返回查询到的员工信息,判断是否为null,判断成功或者失败
直接登陆的功能有漏洞,开发的接口功能在服务端没有做任何的判断,就去实现,所以无论用于是否登陆,都能执行数据的操作,所以需要登陆校验
登陆校验
HTTP协议是无状态协议,每次请求都是独立的,下次的请求不会携带上一次的数据,所以我们在执行业务操作的时候,服务器也不知道这个员工是否登陆了
解决方法:
1.登陆标记
2.同意拦截,登陆校验
会话技术
会话跟踪技术有两种:
- Cookie(客户端会话跟踪技术)
- 数据存储在客户端浏览器当中
- Session(服务端会话跟踪技术)
- 数据存储在储在服务端
- 令牌技术
在用户打开浏览器第一次访问服务器的时候,这个会话就建立了,直到有任何一方断开连接,此时会话就结束了。在一次会话当中,是可以包含多次请求和响应的。
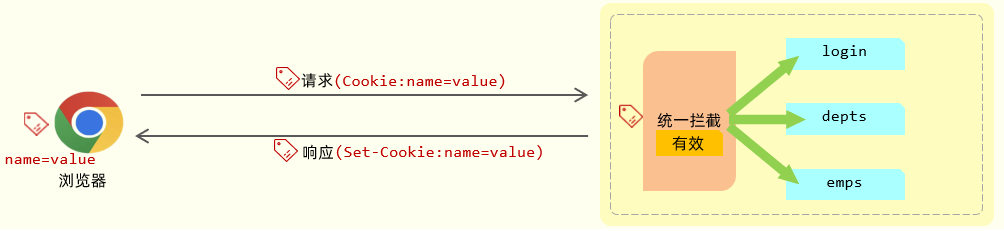
方案一:cookie
cookie是会话跟踪技术,存储在客户端浏览器的,第一次发起请求的时候,在服务器设置一个cookie,在cookie中存储用户相关的一些数据信息,例如:登陆的用户名称,id等等
之后服务端在给客户端响应的时候,同时会将cookie响应给浏览器,浏览器收到cookie后,会自动将其存储在浏览器本地,在后面的每一次请求之后,都会将本地存储的cookie自动携带到服务端,服务端就会判断是否存在cookie的数值,如果有,就说明之前已经登陆完成了,,基于cookie的在同一次会话的不同请求之间共享数据。
1 | cookie会话跟踪技术的主要过程 |
cookie是浏览器HTTP协议之中所支持的数据,所以
用了 3 个自动:
服务器会 自动 的将 cookie 响应给浏览器。
浏览器接收到响应回来的数据之后,会 自动 的将 cookie 存储在浏览器本地。
在后续的请求当中,浏览器会 自动 的将 cookie 携带到服务器端。
cookie的优缺点
优点:HTTP协议之中支持的技术,浏览器自动响应,存储cookie,无需我们手动进行
缺点:
1 | 移动端无法使用cookie,浏览器设置中可以自己禁止使用cookie |
补充:区分跨域的维度:
- 协议
- IP/协议
- 端口
只要上述的三个维度有任何一个维度不同,那就是跨域操作
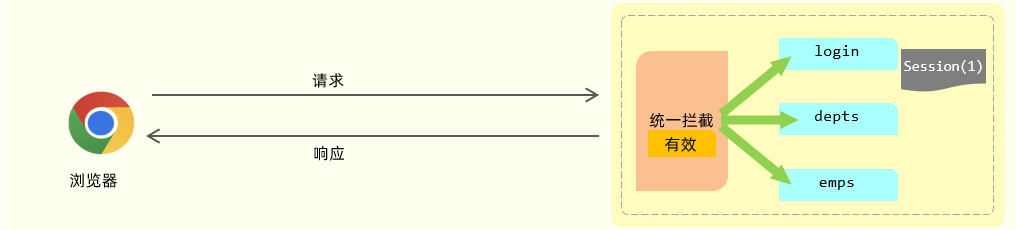
方案二:Session会话跟踪
底层基于cookie实现的,但是存储在服务器端,相较于cookie更安全一些
前面介绍的时候,我们提到Session,它是服务器端会话跟踪技术,所以它是存储在服务器端的。而 Session 的底层其实就是基于我们刚才所介绍的 Cookie 来实现的。
获取Session

如果我们现在要基于 Session 来进行会话跟踪,浏览器在第一次请求服务器的时候,我们就可以直接在服务器当中来获取到会话对象Session。如果是第一次请求Session ,会话对象是不存在的,这个时候服务器会自动的创建一个会话对象Session 。而每一个会话对象Session ,它都有一个ID(示意图中Session后面括号中的1,就表示ID),我们称之为 Session 的ID。
响应Cookie (JSESSIONID)
接下来,服务器端在给浏览器响应数据的时候,它会将 Session 的 ID 通过 Cookie 响应给浏览器。其实在响应头当中增加了一个 Set-Cookie 响应头。这个 Set-Cookie 响应头对应的值是不是cookie? cookie 的名字是固定的 JSESSIONID 代表的服务器端会话对象 Session 的 ID。浏览器会自动识别这个响应头,然后自动将Cookie存储在浏览器本地。
查找Session
接下来,在后续的每一次请求当中,都会将 Cookie 的数据获取出来,并且携带到服务端。接下来服务器拿到JSESSIONID这个 Cookie 的值,也就是 Session 的ID。拿到 ID 之后,就会从众多的 Session 当中来找到当前请求对应的会话对象Session。
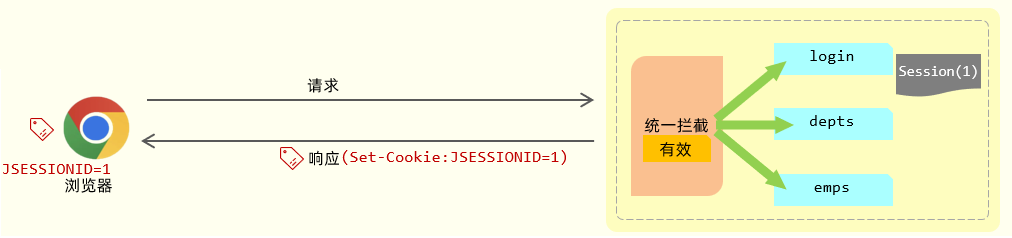

优缺点
- 优点:Session是存储在服务端的,安全
- 缺点:
- 服务器集群环境下无法直接使用Session
- 移动端APP(Android、IOS)中无法使用Cookie
- 用户可以自己禁用Cookie
- Cookie不能跨域
1 | 1.客户端发起请求: 用户在浏览器中输入网址或点击链接,向服务器发起请求。 |
一般企业项目不会部署在同一个服务器上的,因为一个挂了就没法访问了,所以是服务器集群
会有一个均衡负载服务器,将前端请求均匀的分发给集群的服务器
方案三:令牌技术
在请求登陆接口的时候,如果登陆成功,就生成一个令牌,令牌就是用户的合法身份凭证,接下来响应数据的时候,将令牌响应给前端
接下来我们在前端程序当中接收到令牌之后,就需要将这个令牌存储起来。这个存储可以存储在 cookie 当中,也可以存储在其他的存储空间(比如:localStorage)当中。
接下来,在后续的每一次请求当中,都需要将令牌携带到服务端。携带到服务端之后,接下来我们就需要来校验令牌的有效性。如果令牌是有效的,就说明用户已经执行了登录操作,如果令牌是无效的,就说明用户之前并未执行登录操作。
优缺点
- 优点:
- 支持PC端、移动端
- 解决集群环境下的认证问题
- 减轻服务器的存储压力(无需在服务器端存储)
- 缺点:需要自己实现(包括令牌的生成、令牌的传递、令牌的校验)
JWT令牌:JSON Web Token
定义了一种简洁的,自包含的,用于通信双方以JSON数据格式安全传递信息,由于数字签名的存在,这些信息是可靠的。
组成:三部分组成
第一部分:head头,记录令牌的类型,签名是算法
第二部分:payload有效载荷,携带一些自定义,默认的信息
第三部分:数字签名:防止token被篡改等

JWT是如何将原始的JSON格式数据,转变为字符串的呢?
其实在生成JWT令牌时,会对JSON格式的数据进行一次编码:进行base64编码
Base64:是一种基于64个可打印的字符来表示二进制数据的编码方式。既然能编码,那也就意味着也能解码。所使用的64个字符分别是A到Z、a到z、 0- 9,一个加号,一个斜杠,加起来就是64个字符。任何数据经过base64编码之后,最终就会通过这64个字符来表示。当然还有一个符号,那就是等号。等号它是一个补位的符号
需要注意的是Base64是编码方式,而不是加密方式。
jwt令牌的应用场景:登录认证
1 | 1.登陆成功后,生成一个jwt令牌,并且返回给前端 |
生成JWT令牌:引入依赖
1 | <!-- JWT依赖--> |
调用依赖jar包中的相关函数,实现JWT令牌的生成和校验,具体代码如下
1 | public class JwtUtils { |
过滤器Filter
Filter是过滤器,是Javaweb三大组件之一:Servlet,Filter,Listener
把资源对应的请求拦截下来,实现过滤,过滤器处理完毕以后,才能够访问对应的资源
应用场景:比如:统一校验,统一编码处理,敏感字符处理等
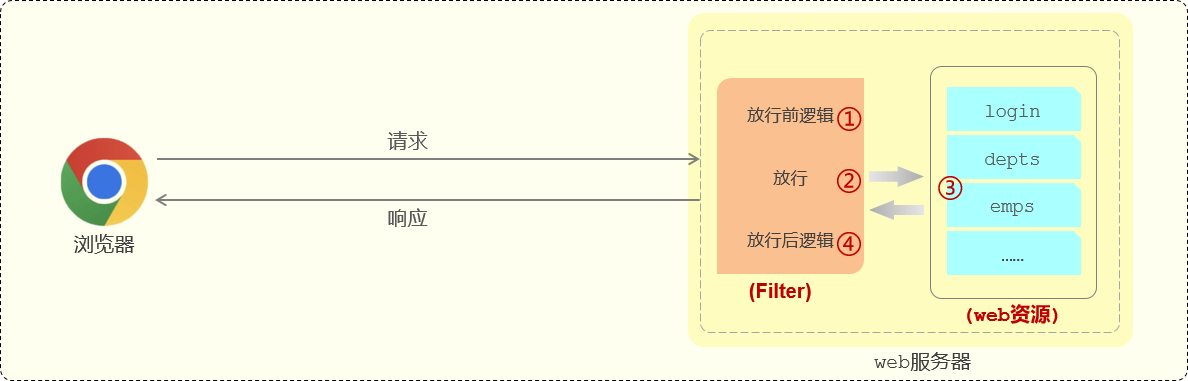
1.定义过滤器:定义一个类,实现servlet中的Filter接口,并且重写其方法
Filter中有三个方法,分别对应
init过滤器的初始化,web服务器启动的时候 会自动创建Filter过滤器对象
doFilter拦截到后调用,每一次拦截到请求之后都会调用
destroy销毁方法后调用,关闭服务的时候会调用
2.配置过滤器:在Filter类上加@WebFilter注解@WebFilter(urlPatterns = “/*”)//表示拦截所有的请求
由于springboot中不包含对web组件servlet的支持,所以要在引导类上加@ServletComponentScan
开启servlet组件的支持。
1 | //配置过滤器要拦截的请求路径( /* 表示拦截浏览器的所有请求 ) |
执行流程我们搞清楚之后,接下来再来介绍一下过滤器的拦截路径,Filter可以根据需求,配置不同的拦截资源路径:
| 拦截路径 | urlPatterns值 | 含义 |
|---|---|---|
| 拦截具体路径 | /login | 只有访问 /login 路径时,才会被拦截 |
| 目录拦截 | /emps/* | 访问/emps下的所有资源,都会被拦截 |
| 拦截所有 | /* | 访问所有资源,都会被拦截 |
过滤器链:一个web中,可以配置多个过滤器,形成一个过滤器链
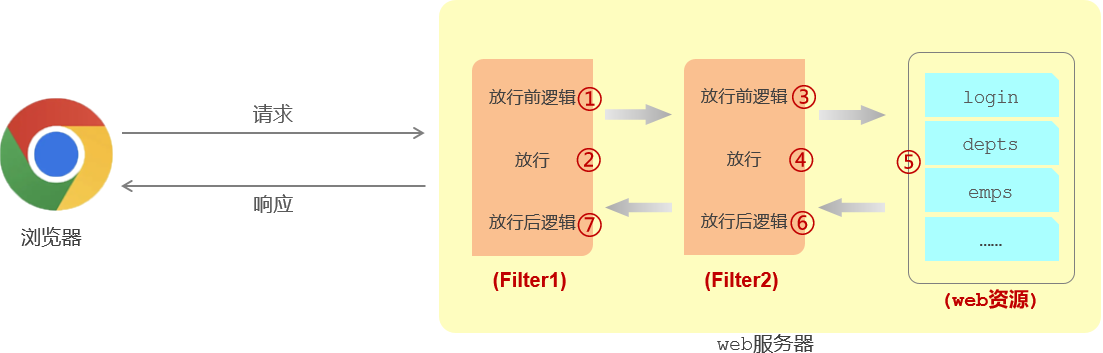
过滤器链的执行顺序:通过注解@WebFilter配置的过滤器,优先级是通过按照过滤器的类名称(字符串)自然排序
登陆校验流程
-在doFilter函数中具体要操作的
1 | 1.获取请求url |
1 |
|
拦截器
类似于过滤器,是springboot框架中提供的,用来动态拦截控制方法的执行
在拦截器中,拦截前端发起的请求,将登陆校验的逻辑全部写在拦截器当中,
拦截器的使用步骤:1.定义拦截器,2.注册配置拦截器
自定义拦截器:实现HandlerInterceptor接口,并且重写其所有方法
1 | //自定义拦截器 |
注册配置拦截器:实现WebMvcConfigurer接口,并且重写addInterceptor方法
1 | //说明该类是配置类 |
拦截路径:首先我们先来看拦截器的拦截路径的配置,在注册配置拦截器的时候,我们要指定拦截器的拦截路径,通过addPathPatterns("要拦截路径")方法,就可以指定要拦截哪些资源。
在入门程序中我们配置的是/**,表示拦截所有资源,而在配置拦截器时,不仅可以指定要拦截哪些资源,还可以指定不拦截哪些资源,只需要调用excludePathPatterns("不拦截路径")方法,指定哪些资源不需要拦截。
在拦截器中除了可以设置/**拦截所有资源外,还有一些常见拦截路径设置:
| 拦截路径 | 含义 | 举例 |
|---|---|---|
| /* | 一级路径 | 能匹配/depts,/emps,/login,不能匹配 /depts/1 |
| /** | 任意级路径 | 能匹配/depts,/depts/1,/depts/1/2 |
| /depts/* | /depts下的一级路径 | 能匹配/depts/1,不能匹配/depts/1/2,/depts |
| /depts/** | /depts下的任意级路径 | 能匹配/depts,/depts/1,/depts/1/2,不能匹配/emps/1 |
拦截器和过滤器的执行流程:

1.Tomcat并不识别所编写的Controller程序,但是它识别Servlet程序,所以在Spring的Web环境中提供了一个非常核心的Servlet:DispatcherServlet(前端控制器),所有请求都会先进行到DispatcherServlet,再将请求转给Controller。
1 | Filter过滤器和Interceptor拦截器 |
异常处理
1.在所有的Controller的方法中,进行try…catch处理(代码臃肿)
2.全局异常处理:定义全局异常处理器
- 定义全局异常处理器非常简单,就是定义一个类,在类上加上一个注解@RestControllerAdvice,加上这个注解就代表我们定义了一个全局异常处理器。
- 在全局异常处理器当中,需要定义一个方法来捕获异常,在这个方法上需要加上注解@ExceptionHandler。通过@ExceptionHandler注解当中的value属性来指定我们要捕获的是哪一类型的异常。
@RestControllerAdvice
public class GlobalExceptionHandler {
1 |
|
事务管理&AOP
事务:事务是一组操作的集合,这些操作要么同时成功,要么同时失败
事务的操作主要有三步:
- 开启事务(一组操作开始前,开启事务):start transaction / begin ;
- 提交事务(这组操作全部成功后,提交事务):commit ;
- 回滚事务(中间任何一个操作出现异常,回滚事务):rollback ;
@Transactional注解:
1 | @Transaction作用:在当前方法执行前开启事务,方法执行完毕后结束事务,如果在这个方法执行的过程中出现了异常,就会进行事务的回滚操作 |
事物进阶:
@Transaction中的两个属性
1.事物回滚的异常属性:rollbackFor():
2.事物传播行为:propagation()
1 |
|
propagation:
用来控制事务的传播属性,就是当一个事物方法被另一个事物方法调用时候,这个事物方法该如何进行事务控制
我们要想控制事务的传播行为,在@Transactional注解的后面指定一个属性propagation,通过 propagation 属性来指定传播行为。接下来我们就来介绍一下常见的事务传播行为。
| 属性值 | 含义 |
|---|---|
| REQUIRED | 【默认值】需要事务,有则加入,无则创建新事务 |
| REQUIRES_NEW | 需要新事务,无论有无,总是创建新事务 |
| SUPPORTS | 支持事务,有则加入,无则在无事务状态中运行 |
| NOT_SUPPORTED | 不支持事务,在无事务状态下运行,如果当前存在已有事务,则挂起当前事务 |
| MANDATORY | 必须有事务,否则抛异常 |
| NEVER | 必须没事务,否则抛异常 |
| … |
对于这些事务传播行为,我们只需要关注以下两个就可以了:
- REQUIRED(默认值)
- REQUIRES_NEW
AOP:面相切面编程
AOP:Aspect Oriented Programming 就是面向特定方法的编程
而AOP面向方法编程,就可以做到在不改动这些原始方法的基础上,针对特定的方法进行功能的增强。
AOP的作用:在程序运行期间在不修改源代码的基础上对已有方法进行增强(无侵入性: 解耦)
比如:我们只想通过 部门管理的 list 方法的执行耗时,那就只有这一个方法是原始业务方法。 而如果,我们是先想统计所有部门管理的业务方法执行耗时,那此时,所有的部门管理的业务方法都是 原始业务方法。 那面向这样的指定的一个或多个方法进行编程,我们就称之为 面向切面编程。
AOP面向切面编程和OOP面向对象编程一样,它们都仅仅是一种编程思想,而动态代理技术是这种思想最主流的实现方式。而Spring的AOP是Spring框架的高级技术,旨在管理bean对象的过程中底层使用动态代理机制,对特定的方法进行编程(功能增强)。
优势:减少重复代码。提高开发效率,维护方便
AOP的快速入门:
1.导入依赖
1 | <dependency> |
2.编写AOP入门程序:根据特定方法根据业务需要编程
1 |
|
AOP的功能:记录操作日志,权限控制,事务管理
优势:代码无侵入,减少了重复代码,提高开发效率,维护方便
AOP的核心概念:
1.连接点:JoinPiont,可以被AOP控制的方法
2.通知:Advice,指哪儿些重复方法,也就是共性功能(最终体现为一个方法),
3.切入点:PointCut,匹配连接点的条件,通知仅会在切入点方法执行时被应用
4.切面:Aspect,描述通知与切入点对应关系(通知+切入点),切面在的类,通常用切面类表示,被@Aspect注解标识的类
5.目标对象:Target,通知所应用的对象
Spring的AOP底层是基于动态代理的技术来实现的,也就是说,在程序运行的时候,会自动的基于动态代理技术为目标对象生成一个对应的代理对象,在代理对象中就会对目标对象中的原始方法的功能进行增强。

AOP进阶
1.通知类型
Spring中AOP的通知类型:
- @Around:环绕通知,此注解标注的通知方法在目标方法前、后都被执行
- @Before:前置通知,此注解标注的通知方法在目标方法前被执行
- @After :后置通知,此注解标注的通知方法在目标方法后被执行,无论是否有异常都会执行
- @AfterReturning : 返回后通知,此注解标注的通知方法在目标方法后被执行,有异常不会执行
- @AfterThrowing : 异常后通知,此注解标注的通知方法发生异常后执行
在使用通知时的注意事项:
- @Around环绕通知需要自己调用 ProceedingJoinPoint.proceed() 来让原始方法执行,其他通知不需要考虑目标方法执行
- @Around环绕通知方法的返回值,必须指定为Object,来接收原始方法的返回值,否则原始方法执行完毕,是获取不到返回值的。
怎么来解决这个切入点表达式重复的问题? 答案就是:抽取
Spring提供了@PointCut注解,该注解的作用是将公共的切入点表达式抽取出来,需要用到时引用该切入点表达式即可。
1 |
|
需要注意的是:当切入点方法使用private修饰时,仅能在当前切面类中引用该表达式, 当外部其他切面类中也要引用当前类中的切入点表达式,就需要把private改为public,而在引用的时候,具体的语法为:
全类名.方法名(),具体形式如下:
1 |
|
通过以上程序运行可以看出在不同切面类中,默认按照切面类的类名字母排序:
- 目标方法前的通知方法:字母排名靠前的先执行
- 目标方法后的通知方法:字母排名靠前的后执行
如果我们想控制通知的执行顺序有两种方式:
- 修改切面类的类名(这种方式非常繁琐、而且不便管理)
- 使用Spring提供的@Order注解
使用@Order注解,控制通知的执行顺序:
通知的执行顺序大家主要知道两点即可:
- 不同的切面类当中,默认情况下通知的执行顺序是与切面类的类名字母排序是有关系的
- 可以在切面类上面加上@Order注解,来控制不同的切面类通知的执行顺序
3.切入点表达式
切入点表达式:
描述切入点方法的一种表达式
作用:主要用来决定项目中的哪些方法需要加入通知
常见形式:
- execution(……):根据方法的签名来匹配
- @annotation(……) :根据注解匹配


excution:主要根据方法的返回值,包名,类名,方法参数,等信息来匹配,语法为
1 |
其中带?的表示可以省略的部分
访问修饰符:可省略(比如: public、protected)
包名.类名: 可省略
throws 异常:可省略(注意是方法上声明抛出的异常,不是实际抛出的异常)
示例:
1 |
可以使用通配符描述切入点
*:单个独立的任意符号,可以通配任意返回值、包名、类名、方法名、任意类型的一个参数,也可以通配包、类、方法名的一部分..:多个连续的任意符号,可以通配任意层级的包,或任意类型、任意个数的参数
切入点表达式的语法规则:
- 方法的访问修饰符可以省略
- 返回值可以使用
*号代替(任意返回值类型) - 包名可以使用
*号代替,代表任意包(一层包使用一个*) - 使用
..配置包名,标识此包以及此包下的所有子包 - 类名可以使用
*号代替,标识任意类 - 方法名可以使用
*号代替,表示任意方法 - 可以使用
*配置参数,一个任意类型的参数 - 可以使用
..配置参数,任意个任意类型的参数
切入点表达式示例
省略方法的修饰符号
1
execution(void com.itheima.service.impl.DeptServiceImpl.delete(java.lang.Integer))
使用
*代替返回值类型1
execution(* com.itheima.service.impl.DeptServiceImpl.delete(java.lang.Integer))
使用
*代替包名(一层包使用一个*)1
execution(* com.itheima.*.*.DeptServiceImpl.delete(java.lang.Integer))
使用
..省略包名1
execution(* com..DeptServiceImpl.delete(java.lang.Integer))
使用
*代替类名1
execution(* com..*.delete(java.lang.Integer))
使用
*代替方法名1
execution(* com..*.*(java.lang.Integer))
使用
*代替参数1
execution(* com.itheima.service.impl.DeptServiceImpl.delete(*))
使用
..省略参数1
execution(* com..*.*(..))
@annotation
要匹配多个无规则的方法,比如list和delete方法,基于excution这种切入表达式描述起来就很不方便,将两个切入点表达式组合在一起,是比较繁琐的
实现步骤:
1.编写自定义注解
2.在业务类要作为连接点的方法上添加自定义注解
自定义注解类:MyLog
1 |
|
切面类:
1 |
|
业务类:DeptServiceImpl
1 |
|
这样就能在调用delete方法的时候,匹配当前定义的注解,执行前置通知和后置通知了
总结:
1 | - execution切入点表达式 |
3.4连接点
连接点:简单来说就是可以被AOP控制的方法
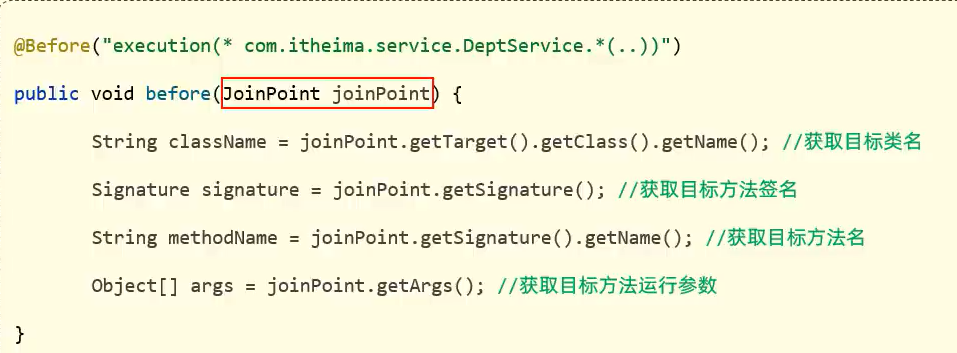
在spring中用JoinPoint抽象了连接点,用它可以获得方法执行的先关信息,比如方法的类名,方法名称, 方法参数等等
1.对于@Around通知,获取连接点的信息只能使用ProceedingJoinPoint类型
2.对于其他四种,after before AfterReturnning AfterThrowing
获取连接点的信息只能用JointPoint,它是ProceedingJoinPoint的父类型
1 | //环绕通知 |
AOP 案例
1 | 需求:将案例中增、删、改相关接口的操作日志记录到数据库表中 |
1 | 实现具体思路 |
Springboot原理
1.配置文件的优先级
在SpringBoot项目当中,常见的属性配置方式有5种, 3种配置文件,加上2种外部属性的配置(Java系统属性、命令行参数)。通过以上的测试,我们也得出了优先级(从低到高):
- application.yaml(忽略)
- application.yml
- application.properties
- java系统属性(-Dxxx=xxx)
- 命令行参数(–xxx=xxx)
2.Bean管理
前面讲过,通过Spring当中提供的注解@Component以及它的三个衍生注解(@Controller@Service@Repository)来声明IOC容器中的bean对象,同时我们也学习了如何为应用程序注入运行时所需要的依赖的bean对象,也就是依赖注入DI
1 | 总的来说,@Repository 注解用于标识数据访问层的组件,而 @Mapper 注解用于标识 MyBatis 的映射接口。 |
1.如何总IOC容器中拿到bean对象
1 | 1. 根据name获取bean |
2.bean对象的作用域配置
前面提到的IOC容器中,默认的bean对象是单列模式(只有一个实例对象)那么如何设置bean对象为非单列呢?需要设置bean的作用域
1 | 在Spring中支持五种作用域,后三种在web环境才生效: |
如何设置一个bean的作用域呢?借助@Scope注解来进行配置作用域

1 | //默认bean的作用域为:singleton (单例) |
3.管理第三方的bean对象
之前我们所配置的bean,像controller、service,dao三层体系下编写的类,这些类都是我们在项目当中自己定义的类(自定义类)。当我们要声明这些bean,也非常简单,我们只需要在类上加上@Component以及它的这三个衍生注解。
如果这个类不是我们自己编写的,而是第三方提供的,那么如何使用和定义第三方的bean?:使用@Bean注解
解决方案一:在启动类上添加@Bean标识的方法 //保持启动类的干净,不推荐使用
1 | //声明第三方bean |
解决方案二:在配置类中定义@Bean标识的方法
如果需要第三方定义的Bean时候,通常会单独定义一个配置类
1 | //配置类 (在配置类当中对第三方bean进行集中的配置管理) |
在方法上添加一个@Bean注解,Spring容器在启动的时候,会自动的调用这个方法,并将方法的返回值声明为Spring容器当中的Bean对象
3.Springboot原理
1 | spring 是一款轻量级的java开发框架,一般指的是spring framework,他是很多模块的集合,包括springboot快速启动,springcloud微服务,spring Data数据库等spring全家桶 |
Springboot之所以能简化Spring的开发,是因为SpringBoot底层提供了两个非常重要的功能,一个是起步依赖,一个是自动配置
起步依赖:
Springboot所提供的起步依赖,可以大大简化pom文件当中的依赖配置,从而解决了Spring框架中依赖配置繁琐的问题
自动配置:
通过自动配置功能就可以打打简化Spring框架在使用Bean的声明以及Bean的配置,我们只需要引入程序开发时候所需要的起步依赖,项目开发时所用到的常见配置都有了,我们直接使用就可以了
3.1起步依赖:
假设没有使用SpringBoot,用的Spring框架进行Web开发,这时候我们需要引入相关依赖
Spring-webmvc依赖,Servlet依赖,aop依赖,JSON处理依赖,Tomcat依赖,还要保证依赖的版本匹配,避免出现版本冲突的问题
如果我们使用了SpringBoot,直接引用web开发的起步依赖,springboot-starter-web起步依赖即可,因为有Maven依赖传递,所需要的依赖就都有了
3.2自动配置:
概述:Springboot的自动配置,就是当Spring容器启动后,一些配置类,Bean对象就自动存储到了IOC容器中,不需要我们手动声明,从而简化了开发,省去了繁琐的配置操作
比如:我们要进行事务管理,要进行AOP切面开发,就不需要手动声明这些Bean对象了,直接注入就可以了
1 | 在IOC容器中,除了我们自己定义的Bean以外,还有很多配置类,这些配置类都是在SpringBoot启动的时候加载进来的配置类,这些配置类加载进来后,也会生成很多的Bean对象,我们并没有声明,却可以通过@Autowired自动注入Bean对象, |
解析自动配置的原理:分析在Springboot中,我们引入对应的依赖后,Springboot是如何将依赖jar包当中提供的Bean以及配置类直接加载到当前项目的springIOC容器当中的
我们先引入第三方的依赖,执行测试方法发现:在Spring容器中没有找到com.example.TokenParse类型的bean对象
1 | 思考:为什么引入的第三方依赖当中的Bean以及配置类,没有生效 |
解决方法:
1.@Component组件扫描、、繁琐不推荐
1 |
|
2.@import导入(使用@import导入的类会被Spring加载到IOC容器当中去)
导入形式主要有以下几种:
- 导入普通类
- 导入配置类
- 导入ImportSelector接口实现类
不推荐,我们不知道第三方具体类,导入繁琐
4.使用第三方提供的@EnableXxxxx注解(推荐),第三方打包好的
只需要在启动类上加上@EnableXxxxx注解即可
3.3原理分析:源码跟踪
SpringBoot启动类的核心注解,@SpringBootApplication开始分析
在@SpringBootApplication包含了注解如下:
1 | 四个元注解: |
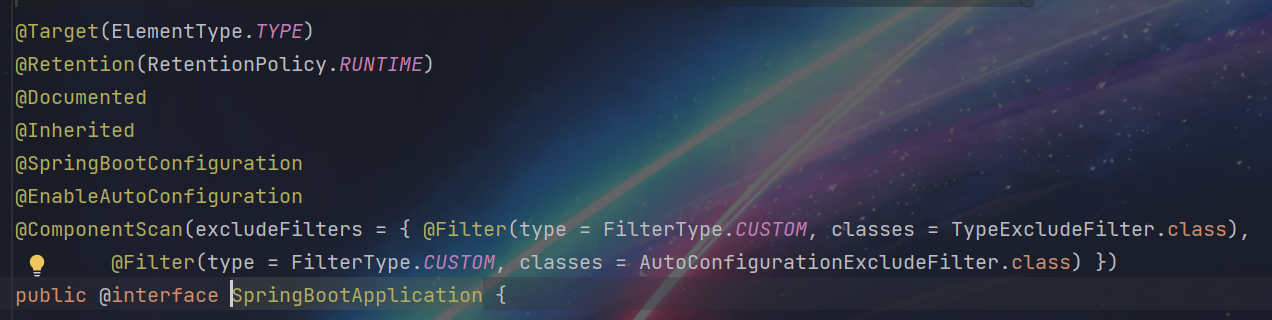
1 | 在@SpringBootApplication注解中包含了: |
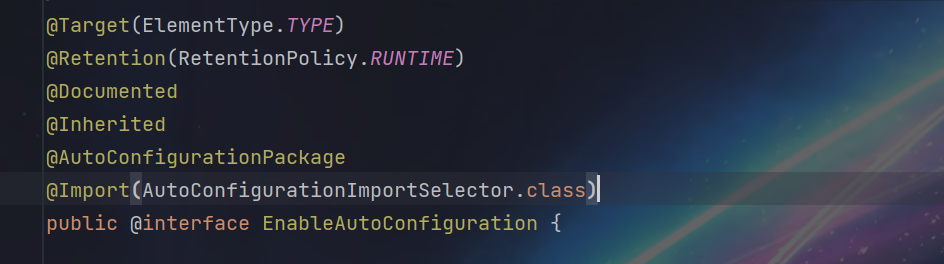
1 | 使用@Import注解,导入了实现ImportSelector接口的实现类。 |
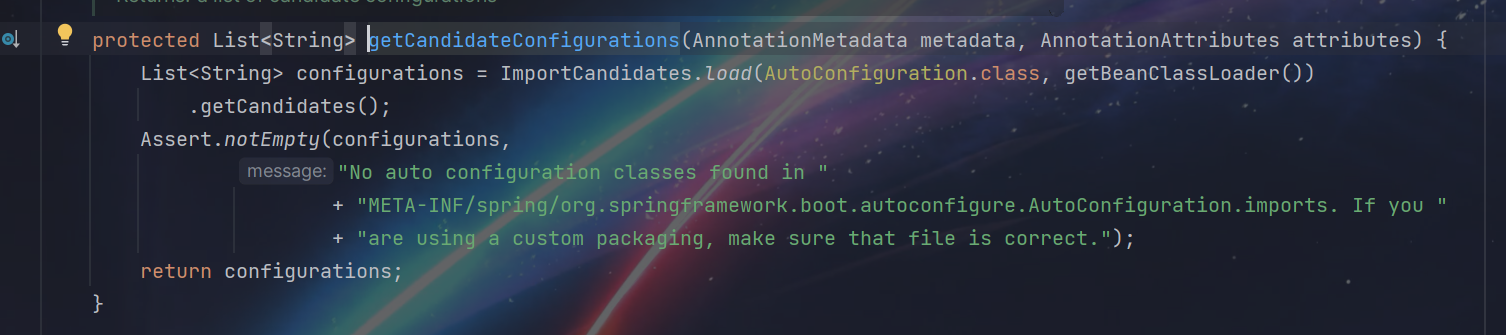
在起步依赖中打开配置文件的所在位置
在测试类的时候,我们直接在测试类中,注入了一个叫gson的Bean对象,用来进行JSON格式转换,虽然我们没有配置对象,但是我们可以直接注入使用,原因就是在SpringBoot在启动时在自动配置类实现了自动配置,我们双击shift进入这个类的源码,
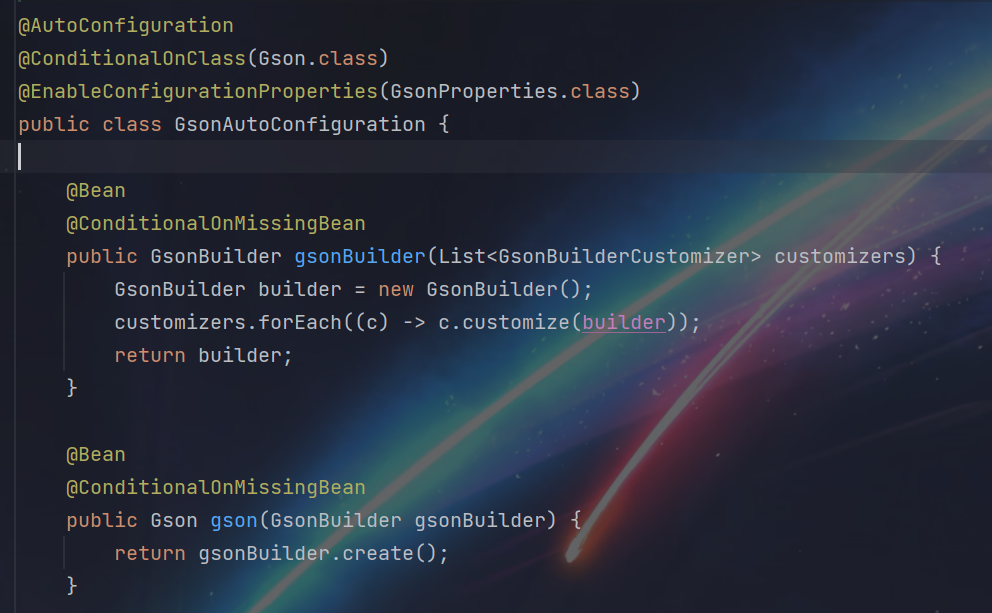
@AutoConfiguration底层就封装了@Configuration注解,表示该类是一个配置类
@Configuration注解的类可以使用@Bean注解来声明Bean,Spring容器会根据这些Bean的定义来创建和管理Bean实例,调用配置类中的@Bean标识的方法,并且把方法的返回值注册到IOC容器中去。
1 | 文件中定义的配置类非常多,而且每个配置类中又可以定义很多的bean,那这些bean都会注册到Spring的IOC容器中吗? |
@Conditional注解
作用:按照一定的条件进行判断,满足相应的条件后,才会注册对应的Bean对象到Spring的IOC容器中
Conditional 是一个父注解,会派生出大量的子注解:
@ConditionalOnBean:当容器里有指定 Bean 的条件下@ConditionalOnMissingBean:当容器里没有指定 Bean 的情况下@ConditionalOnSingleCandidate:当指定 Bean 在容器中只有一个,或者虽然有多个但是指定首选 Bean@ConditionalOnClass:当类路径下有指定类的条件下@ConditionalOnMissingClass:当类路径下没有指定类的条件下@ConditionalOnProperty:指定的属性是否有指定的值@ConditionalOnResource:类路径是否有指定的值@ConditionalOnExpression:基于 SpEL 表达式作为判断条件@ConditionalOnJava:基于 Java 版本作为判断条件@ConditionalOnJndi:在 JNDI 存在的条件下差在指定的位置@ConditionalOnNotWebApplication:当前项目不是 Web 项目的条件下@ConditionalOnWebApplication:当前项目是 Web 项 目的条件下
主要用的有三个:
- @ConditionalOnClass:判断环境中有对应字节码文件,才注册bean到IOC容器。
- @ConditionalOnMissingBean:判断环境中没有对应的bean(类型或名称),才注册bean到IOC容器。
- @ConditionalOnProperty:判断配置文件中有对应属性和值,才注册bean到IOC容器。
底层的自动配置原理总结:
1 | 简单来说就是:SpringBoot 定义了一套接口规范,这套规范规定:SpringBoot 在启动时会扫描外部引用 jar 包中的META-INF/spring.factories文件,将文件中配置的类型信息加载到 Spring 容器(此处涉及到 JVM 类加载机制与 Spring 的容器知识),并执行类中定义的各种操作。对于外部 jar 来说,只需要按照 SpringBoot 定义的标准,就能将自己的功能装置进 SpringBoot。 |
案例:自定义starter分析
业务场景:
我们案例中使用的阿里云oss对象存储服务,阿里云并没有提供起步依赖,这时候用起来就比较繁琐,我们需要1.引入对应依赖 2.在配置文件中配置3.基于官方SDK来改造相应的工具类
这时候我们需要自定义一些公共组件,在这些公共组件中,提前把需要配置的Bean都配置好,到时候直接将对应组件的坐标引入进来,交给Spring自动配置,大大简化开发
需求:自定义起步依赖,完成对阿里云OSS操作工具类AliyunOSSUtils的自动配置
引入起步依赖后,要想使用阿里云OSS,注入AliyunOSSUtils直接使用即可
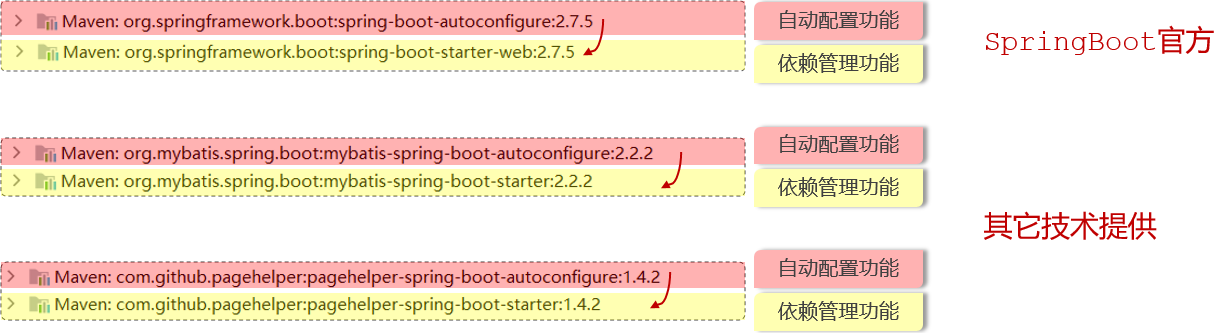
在自定义一个起步依赖starter的时候,按照规范需要定义两个模块:
1.starter模块:进行依赖管理(程序开发过程所需要的依赖,都定义在starter起步依赖中)
2.autoconfigure模块:自动配置模块
1 | 需求明确了,接下来我们再来分析一下具体的实现步骤: |
1 | 前两步骤好说,在autoconfiguration中配置好相关依赖,再在starter模块中引入autoconfiguration依赖即可 |
1 |
|
1 |
|
web开发总结:
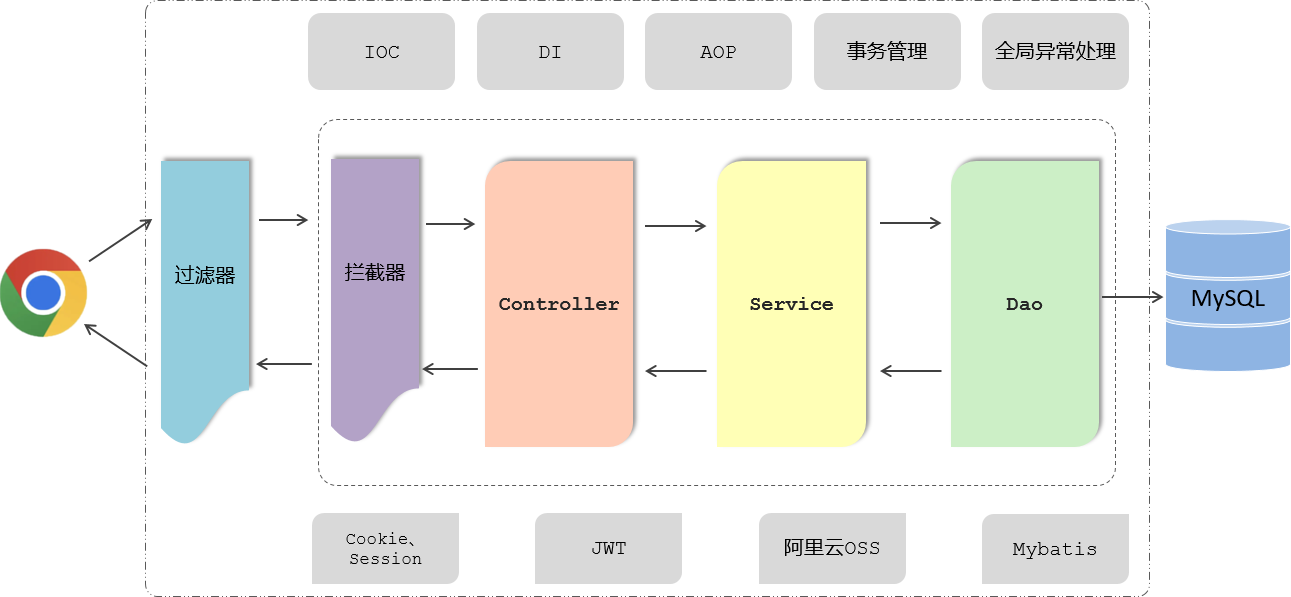
后端开发流程:
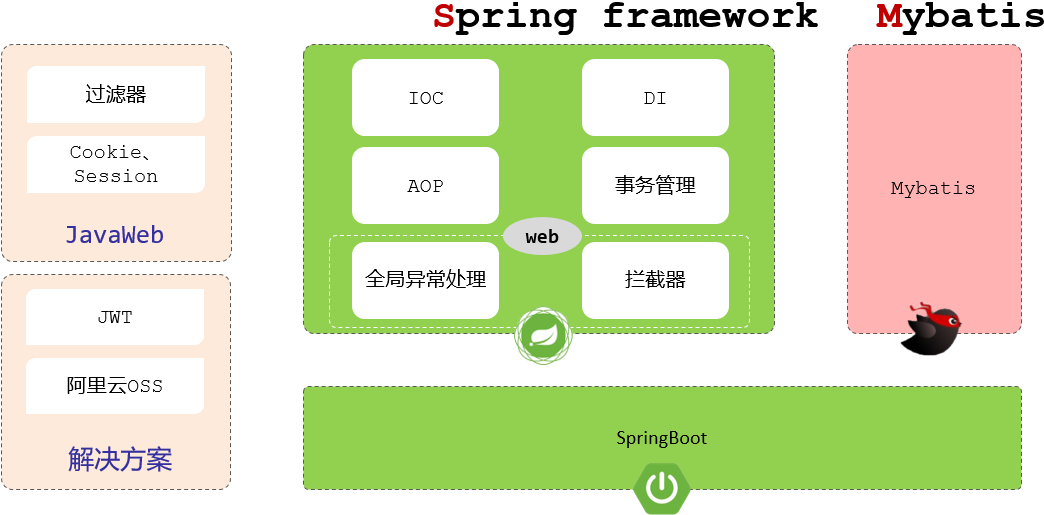
我们在学习这些web后端开发技术的时候,我们都是基于主流的SpringBoot进行整合使用的。而SpringBoot又是用来简化开发,提高开发效率的。
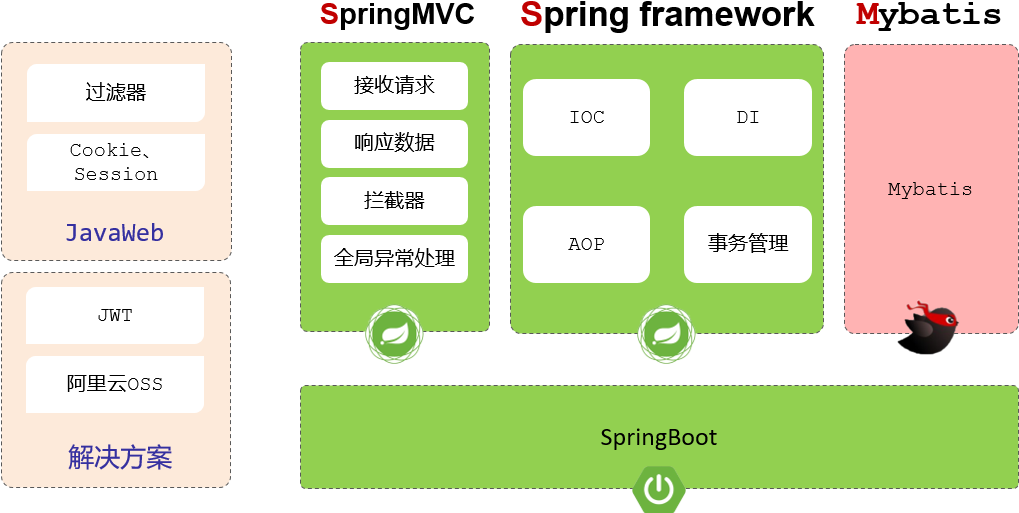
而Spring框架的web开发模块,我们也称为:SpringMVC
SpringMVC,SpringFramework,Mybatis俗称SSM
基于传统的SSM框架进行整合项目开发会比较繁琐,而且开发效率低,所以现在的企业开发当中,基本上都是基于SpringBoot整合SSM进行项目开发的
web后端开发内容完结撒花!
Maven高级
Maven高级内容包括:
- 分模块设计与开发
- 继承与聚合
- 私服
1.分模块设计与开发
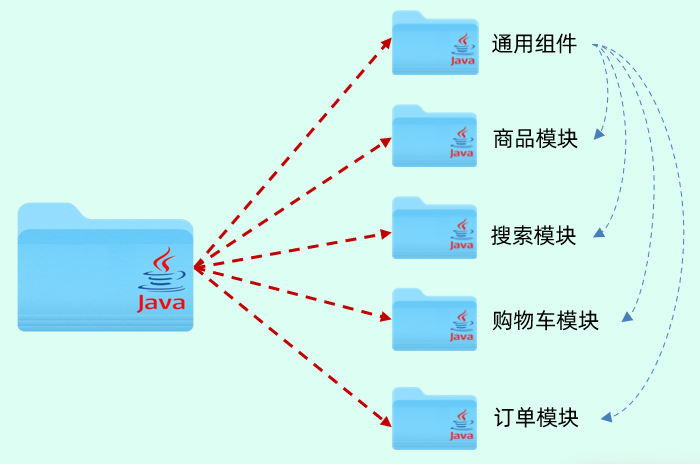
而且分模块设计之后,如果我们需要用到另外一个模块的功能,我们直接依赖模块就可以了。比如商品模块、搜索模块、购物车订单模块都需要依赖于通用组件当中封装的一些工具类,我只需要引入通用组件的坐标就可以了。
分模块设计就是将项目按照功能/结构拆分成若干个子模块,方便项目的管理维护、拓展,也方便模块键的相互调用、资源共享。

方案一:直接依赖我们当前项目 tlias-web-management ,但是存在两大缺点:
- 这个项目当中包含所有的业务功能代码,而想共享的资源,仅仅是pojo下的实体类,以及 utils 下的工具类。如果全部都依赖进来,项目在启动时将会把所有的类都加载进来,会影响性能。
- 如果直接把这个项目都依赖进来了,那也就意味着我们所有的业务代码都对外公开了,这个是非常不安全的。
方案二:分模块设计
1.将pojo包下的实体类,抽取到一个Maven模块tlias-pojo
2.将utils包下的工具类,抽取到一个Maven模块中tlias-utils
3.在具体的工程文件中,直接引入对应的依赖即可
注意:分模块开发需要先针对模块功能进行设计,再进行编码。不会先将工程开发完毕,然后进行拆分。
2.继承与聚合
在案例项目分模块开发之后啊,我们会看到tlias-pojo、tlias-utils、tlias-web-management中都引入了一个依赖 lombok 的依赖。我们在三个模块中分别配置了一次。
功能虽然能实现,但是很繁琐
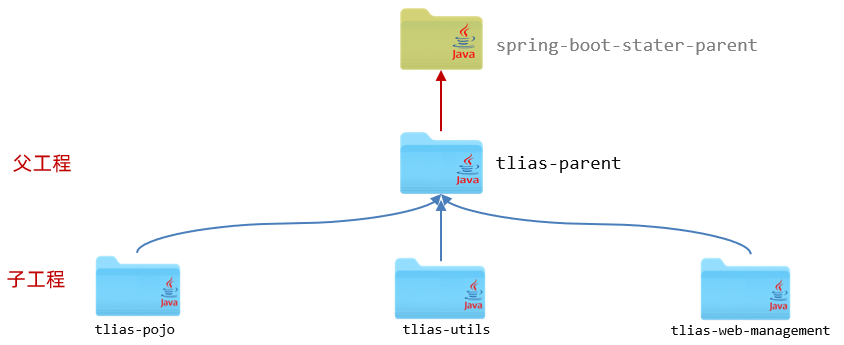
2.1继承
我们可以再创建一个父工程 tlias-parent ,然后让上述的三个模块 tlias-pojo、tlias-utils、tlias-web-management 都来继承这个父工程 。 然后再将各个模块中都共有的依赖,都提取到父工程 tlias-parent中进行配置,只要子工程继承了父工程,依赖它也会继承下来,这样就无需在各个子工程中进行配置了。
Maven不支持多继承,但是支持多继承,与Java类似
所有的SpringBoot工程都有一个父工程,spring-boot-starter-parent。
我们为了将公共的依赖抽离出来,就可以自己创建一个父工程,保存公共的依赖,再由子工程去继承,如下图所示
1 | <groupId>com.itheima</groupId> |
这里打包方式设置为pom,提及到Maven的打包方式:
1 | Maven打包方式: |
在子工程的pom文件中,配置继承关系
1 | <parent> |
2.2版本锁定
场景:如果项目中各个模块都公共的各部分依赖,我们可以定义在父工程中,从而简化子工程的配置,然而在项目开发中,还有一些模块,并不是各个模块共有的,有可能只有其中的一小部分模块使用到了这个依赖
问题:如果项目拆分的够多,每次更新版本,我们都找得到这个项目中的每一个模块,一个一个改,很容易出现问题,遗漏掉一个模块,忘记更换版本的情况。
这时候就需要Maven的版本锁定功能
父工程:
1 | <!--统一管理依赖版本--> |
子工程:
1 | <dependencies> |
1 | 在Maven中,可以在父工程pom文件中,通过<dependencyManagement>来统一管理依赖版本 |
属性配置
我们也可以通过自定义属性以及属性的引用形式,在父工程中,将依赖的版本号进行集中管理和维护,具体的语法为:
1). 自定义属性
1 | <properties> |
2). 引用属性
1 | <dependency> |
我们就可以在父工程中,将所有的版本号,都集中管理维护出来。
面试题:<dependencyManagement> 与 <dependencies> 的区别是什么?
<dependencies>是直接依赖,在父工程配置了依赖,子工程会直接继承下来。<dependencyManagement>是统一管理依赖版本,不会直接依赖,还需要在子工程中引入所需依赖(无需指定版本)
2.3聚合
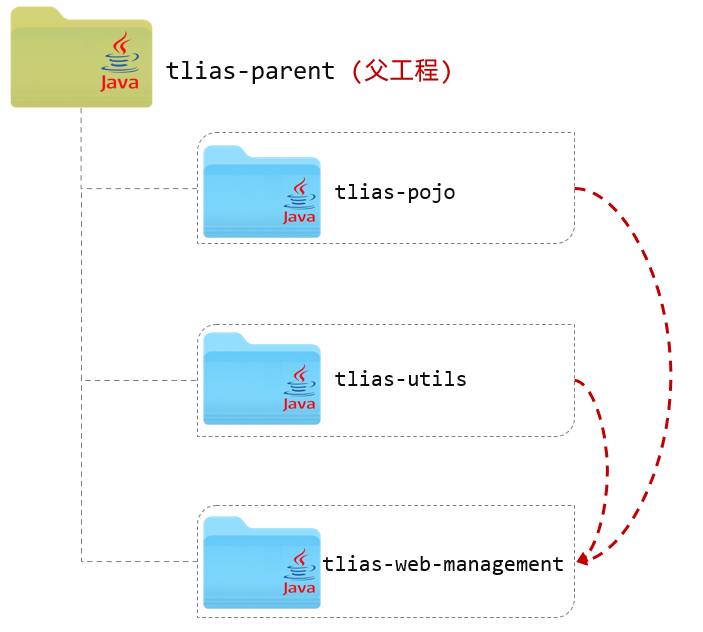
分模块设计和开发之后,我们的项目被拆分了很多模块,比如如上图,我们在打包management的时候,需要将parent,pojo,utils分别执行install生命周期安装到Maven的本地仓库,在针对management模块执行package打包操作。就很繁琐
通过Maven聚合就能够实现项目的统一构建(清理,编译,测试,打包,安装等)
聚合:将多个模块组织成一个整体
聚合工程:一个不具有业务功能的空工程,有且只有一个pom文件,一般来讲,继承关系中的父工程和聚合工程是同一个
作用:快速构建项目,无需根据依赖关系构建,直接在聚合工程上构建即可
实现:在聚合工程中,通过
1 | <!--聚合其他模块--> |
2.3 继承与聚合对比
作用
聚合用于快速构建项目
继承用于简化依赖配置、统一管理依赖
相同点:
聚合与继承的pom.xml文件打包方式均为pom,通常将两种关系制作到同一个pom文件中
聚合与继承均属于设计型模块,并无实际的模块内容
不同点:
聚合是在聚合工程中配置关系,聚合可以感知到参与聚合的模块有哪些
继承是在子模块中配置关系,父模块无法感知哪些子模块继承了自己
3.私服
本地搭建私服,供不同的电脑去访问和上传相应的依赖jar包
私服:是一中特殊的远程仓库,架设在局域网内的仓库服务,用来代理与外部的中央仓库,用于解决团队内部资源共享与资源同步问题
依赖查找顺序:本地仓库,私服仓库,中央仓库
资料的上传与下载:
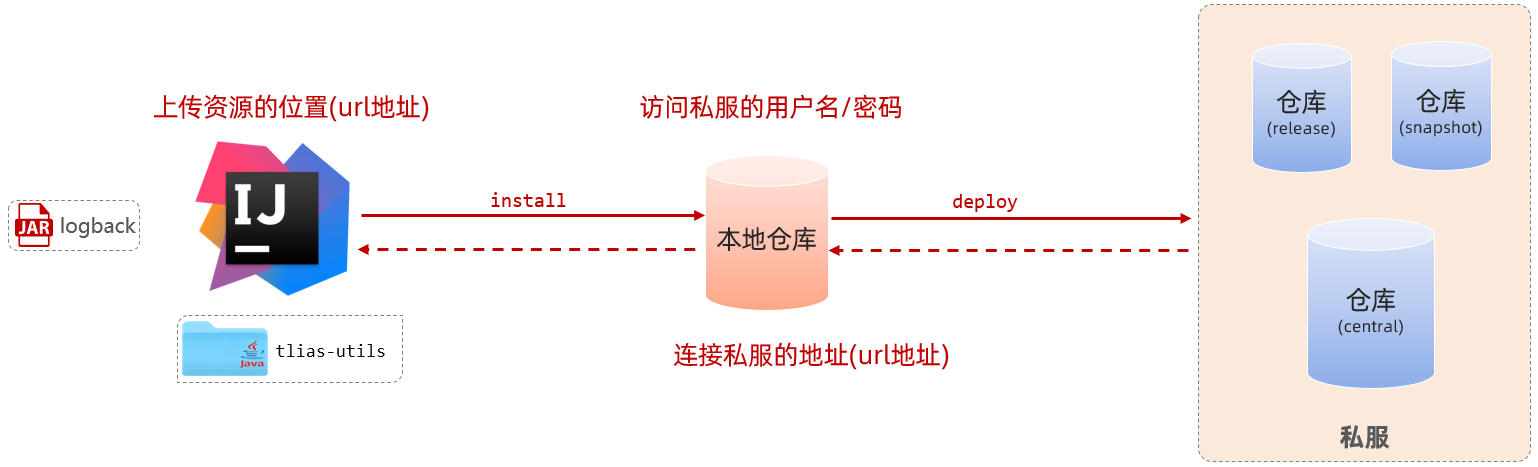
资源上传与下载,我们需要做三步配置,执行一条指令。
第一步配置:在maven的配置文件中配置访问私服的用户名、密码。
第二步配置:在maven的配置文件中配置连接私服的地址(url地址)。
第三步配置:在项目的pom.xml文件中配置上传资源的位置(url地址)。
配置好了上述三步之后,要上传资源到私服仓库,就执行执行maven生命周期:deploy。
私服仓库说明:
- RELEASE:存储自己开发的RELEASE发布版本的资源。
- SNAPSHOT:存储自己开发的SNAPSHOT发布版本的资源。
- Central:存储的是从中央仓库下载下来的依赖。
项目版本说明:
- RELEASE(发布版本):功能趋于稳定、当前更新停止,可以用于发行的版本,存储在私服中的RELEASE仓库中。
- SNAPSHOT(快照版本):功能不稳定、尚处于开发中的版本,即快照版本,存储在私服的SNAPSHOT仓库中。
具体操作:
1.设置私服的访问用户名、密码:在Maven安装目录下conf/settings.xml中的servers中配置
1 | <server> |
2.设置私服依赖下载的仓库组地址(在自己maven安装目录下的conf/settings.xml中的mirrors、profiles中配置)
1 | <mirror> |
1 | <profile> |
3.IDEA的maven工程的pom文件中配置上传(发布)地址(直接在tlias-parent中配置发布地址)
1 | <distributionManagement> |
配置完成之后,我们就可以在tlias-parent中执行deploy生命周期,将项目发布到私服仓库中。







